
TL;DR
Details:
- sk_run_filter is part of the Linux secure computing (seccomp), it filters system calls and their parameters
- seccomp is called for each system call made by all programs inside any docker container, including the MySQL server
- seccomp is not JIT-powered in Linux kernel 3.10 - frequent system calls lead to high CPU consumption in sk_run_filter function
- seccomp is JIT-powered in Linux kernel 4.19
- seccomp is additionally optimized in kernel 5.15 with bitmap cache
- Docker engine uses seccomp, it generates BPF program which is loaded by prctl (PR_SET_SECCOMP) in runc (libcontainer/seccomp/patchbpf/enosys_linux.go)
- The list of allowed system calls is described as a JSON file, usually as a whitelist - 300+ entries, which generates quite long BPF program
- Our MySQL performance drops more than 40% inside the docker container
Recommendations:
- Update to the Linux kernel 5.15 or at least 4.19 if you use docker containers in production
- Mitigation for the older Linux kernels: rewrite the docker’s JSON file from whitelist approach (300+ entries) to the blacklist (for us - about 40 entries). It’s faster to block small amount of system calls than to allow a wider range (like the default docker’s filter does)
- More complex mitigation for older kernels: use an up-to-date libseccomp (version 2.5.4) with binary tree optimization feature. There’re the following options:
- Recompile docker with the latest libseccomp and binary tree optimization patch
- Or turn off current docker security feature totally and load the seccomp’s BPF program manually as the first binary executed inside the docker container, after that fork other processes
Linux kernels 3.10, 4.19 and 5.15 are chosen because they have long term support by comunity and Huawei’s EulerOS.
Problem
MySQL server is deployed inside docker container. The server runs Linux kernel 3.10. Under high load the kernel function sk_run_filter consumes extraordinary high amount of CPU:
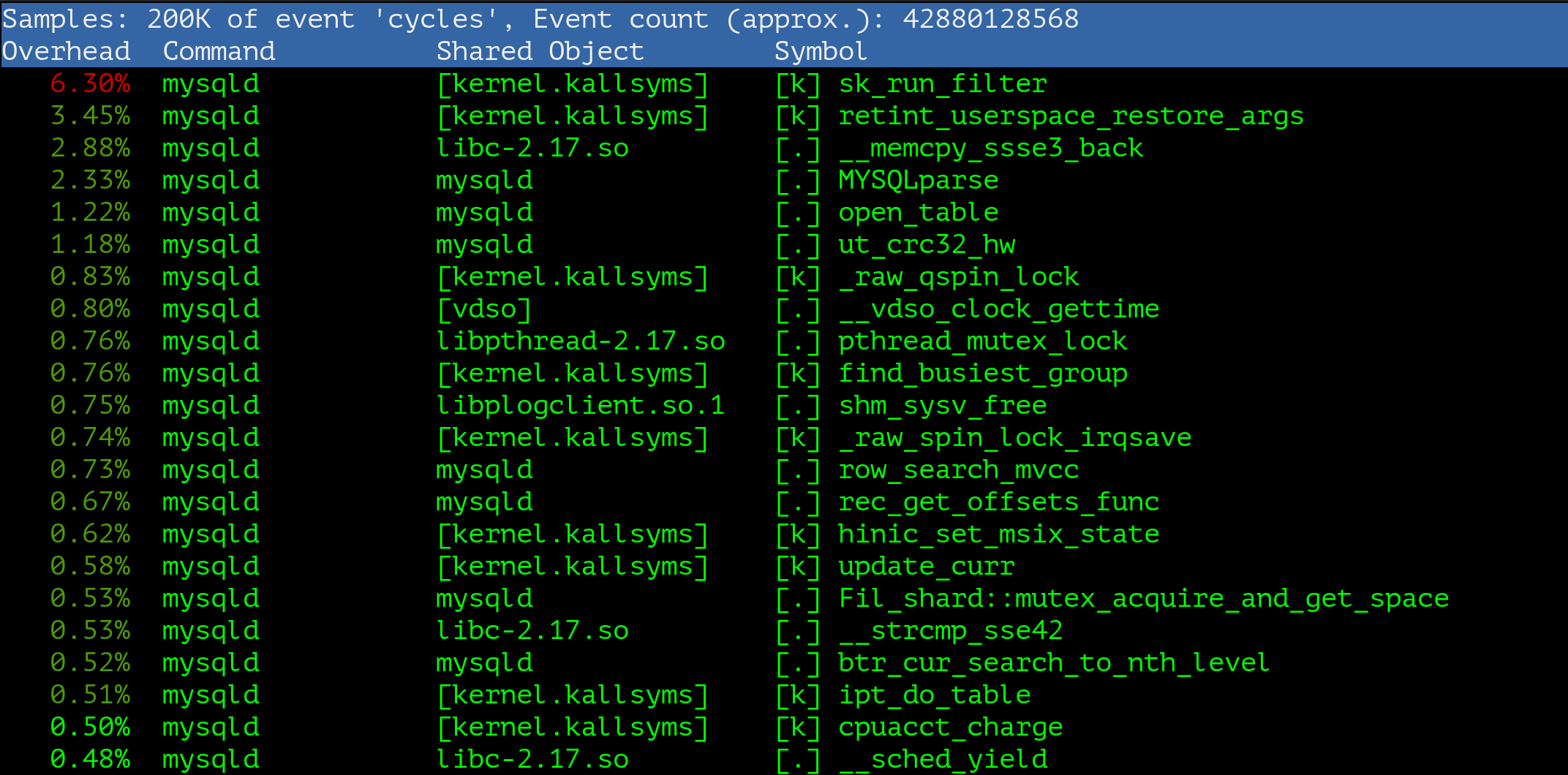
So, there’s where the story starts!
The original BPF
sk_run_filter executes a BPF program in the kernel space. The program is intended for the quite simple virtual machine inside the kernel (one CPU register, very restricted instruction set). It’s main original purpose is to run user defined hooks for the network data. The program instructions are stored in the array and attached via setsockopt (SO_ATTACH_FILTER) system call, for example:
static struct sock_filter bpfcode[6] = {
{ OP_LDH, 0, 0, 12 }, // ldh [12]
{ OP_JEQ, 0, 2, ETH_P_IP }, // jeq #0x800, L2, L5
{ OP_LDB, 0, 0, 23 }, // ldb [23]
{ OP_JEQ, 0, 1, IPPROTO_TCP }, // jeq #0x6, L4, L5
{ OP_RET, 0, 0, 0 }, // ret #0x0
{ OP_RET, 0, 0, -1, }, // ret #0xffffffff
};
int main(int argc, char **argv)
{
// ....
if (setsockopt(sock, SOL_SOCKET, SO_ATTACH_FILTER, &bpf, sizeof(bpf))) {
perror("setsockopt ATTACH_FILTER");
return 1;
}
// ....
}
Let’s look inside the kernel source code, version 3.10.
/**
* sk_run_filter - run a filter on a socket
* @skb: buffer to run the filter on
* @fentry: filter to apply
*
* Decode and apply filter instructions to the skb->data.
* Return length to keep, 0 for none. @skb is the data we are
* filtering, @filter is the array of filter instructions.
* Because all jumps are guaranteed to be before last instruction,
* and last instruction guaranteed to be a RET, we dont need to check
* flen. (We used to pass to this function the length of filter)
*/
unsigned int sk_run_filter(const struct sk_buff *skb,
const struct sock_filter *fentry)
{
void *ptr;
u32 A = 0; /* Accumulator */
u32 X = 0; /* Index Register */
u32 mem[BPF_MEMWORDS]; /* Scratch Memory Store */
u32 tmp;
int k;
/*
* Process array of filter instructions.
*/
for (;; fentry++) {
#if defined(CONFIG_X86_32)
#define K (fentry->k)
#else
const u32 K = fentry->k;
#endif
switch (fentry->code) {
case BPF_S_ALU_ADD_X:
A += X;
continue;
case BPF_S_ALU_ADD_K:
A += K;
continue;
case BPF_S_ALU_SUB_X:
A -= X;
continue;
/*
.....
a lot of case statements
.....
*/
#ifdef CONFIG_SECCOMP_FILTER
case BPF_S_ANC_SECCOMP_LD_W:
A = seccomp_bpf_load(fentry->k);
continue;
#endif
default:
WARN_RATELIMIT(1, "Unknown code:%u jt:%u tf:%u k:%u\n",
fentry->code, fentry->jt,
fentry->jf, fentry->k);
return 0;
}
}
return 0;
}
As we can see, it’s a classic interpreter which executes the BPF, which is very slow. For socket (network subsystem) the JIT compiler was optionally added for some platforms to solve the performance issues, i.e for x86_64 we have one:
#ifdef CONFIG_BPF_JIT
/* ...... */
#define SK_RUN_FILTER(FILTER, SKB) (*FILTER->bpf_func)(SKB, FILTER->insns)
#else
static inline void bpf_jit_compile(struct sk_filter *fp)
{
}
static inline void bpf_jit_free(struct sk_filter *fp)
{
}
#define SK_RUN_FILTER(FILTER, SKB) sk_run_filter(SKB, FILTER->insns)
#endif
/* ...... */
void bpf_jit_compile(struct sk_filter *fp)
{
/* ...... */
/* JITed image shrinks with every pass and the loop iterates
* until the image stops shrinking. Very large bpf programs
* may converge on the last pass. In such case do one more
* pass to emit the final image
*/
for (pass = 0; pass < 10 || image; pass++) {
u8 seen_or_pass0 = (pass == 0) ? (SEEN_XREG | SEEN_DATAREF | SEEN_MEM) : seen;
/* no prologue/epilogue for trivial filters (RET something) */
proglen = 0;
prog = temp;
if (seen_or_pass0) {
EMIT4(0x55, 0x48, 0x89, 0xe5); /* push %rbp; mov %rsp,%rbp */
EMIT4(0x48, 0x83, 0xec, 96); /* subq $96,%rsp */
/* note : must save %rbx in case bpf_error is hit */
if (seen_or_pass0 & (SEEN_XREG | SEEN_DATAREF))
EMIT4(0x48, 0x89, 0x5d, 0xf8); /* mov %rbx, -8(%rbp) */
if (seen_or_pass0 & SEEN_XREG)
CLEAR_X(); /* make sure we dont leek kernel memory */
/* ...... */
if (bpf_jit_enable > 1)
bpf_jit_dump(flen, proglen, pass, image);
if (image) {
bpf_flush_icache(image, image + proglen);
fp->bpf_func = (void *)image;
}
out:
kfree(addrs);
return;
}
The typical usage for SK_RUN_FILTER is the following:
/**
* sk_filter_trim_cap - run a packet through a socket filter
* @sk: sock associated with &sk_buff
* @skb: buffer to filter
* @cap: limit on how short the eBPF program may trim the packet
*
* Run the filter code and then cut skb->data to correct size returned by
* sk_run_filter. If pkt_len is 0 we toss packet. If skb->len is smaller
* than pkt_len we keep whole skb->data. This is the socket level
* wrapper to sk_run_filter. It returns 0 if the packet should
* be accepted or -EPERM if the packet should be tossed.
*
*/
int sk_filter_trim_cap(struct sock *sk, struct sk_buff *skb, unsigned int cap)
{
/* ..... */
rcu_read_lock();
filter = rcu_dereference(sk->sk_filter);
if (filter) {
unsigned int pkt_len = SK_RUN_FILTER(filter, skb); //<<-- HERE
err = pkt_len ? pskb_trim(skb, max(cap, pkt_len)) : -EPERM;
}
rcu_read_unlock();
return err;
}
The code snippets provided above prove that for x86_64 platform the BPF program is JIT- compiled to the native x86_64 machine code, and the bpf_func is invoked. So there should be no sk_run_filter in the perf profile. That means that we observe something different inside our current testing environment.
Seccomp BPF
The secure computing mode is one of the security feature inside the Linux kernel, which provides the ability to filter system calls and its arguments using the BPF mechanism. The BPF program is loaded by prctl (PR_SET_SECCOMP) or seccomp (SECCOMP_SET_MODE_FILTER) system calls. A simple example of how this works for prctl is shown here, where the author forbids write system call doing the following:
#include <errno.h>
#include <linux/audit.h>
#include <linux/bpf.h>
#include <linux/filter.h>
#include <linux/seccomp.h>
#include <linux/unistd.h>
#include <stddef.h>
#include <stdio.h>
#include <sys/prctl.h>
#include <unistd.h>
static int install_filter(int nr, int arch, int error) {
struct sock_filter filter[] = {
BPF_STMT(BPF_LD + BPF_W + BPF_ABS, (offsetof(struct seccomp_data, arch))),
BPF_JUMP(BPF_JMP + BPF_JEQ + BPF_K, arch, 0, 3),
BPF_STMT(BPF_LD + BPF_W + BPF_ABS, (offsetof(struct seccomp_data, nr))),
BPF_JUMP(BPF_JMP + BPF_JEQ + BPF_K, nr, 0, 1),
BPF_STMT(BPF_RET + BPF_K, SECCOMP_RET_ERRNO | (error & SECCOMP_RET_DATA)),
BPF_STMT(BPF_RET + BPF_K, SECCOMP_RET_ALLOW),
};
struct sock_fprog prog = {
.len = (unsigned short)(sizeof(filter) / sizeof(filter[0])),
.filter = filter,
};
if (prctl(PR_SET_NO_NEW_PRIVS, 1, 0, 0, 0)) {
perror("prctl(NO_NEW_PRIVS)");
return 1;
}
if (prctl(PR_SET_SECCOMP, 2, &prog)) {
perror("prctl(PR_SET_SECCOMP)");
return 1;
}
return 0;
}
int main() {
printf("hey there!\n");
install_filter(__NR_write, AUDIT_ARCH_X86_64, EPERM);
printf("something's gonna happen!!\n");
printf("it will not definitely print this here\n");
return 0;
}
Looking into the perf profile ( gathered with children ), we can see the following stack trace:
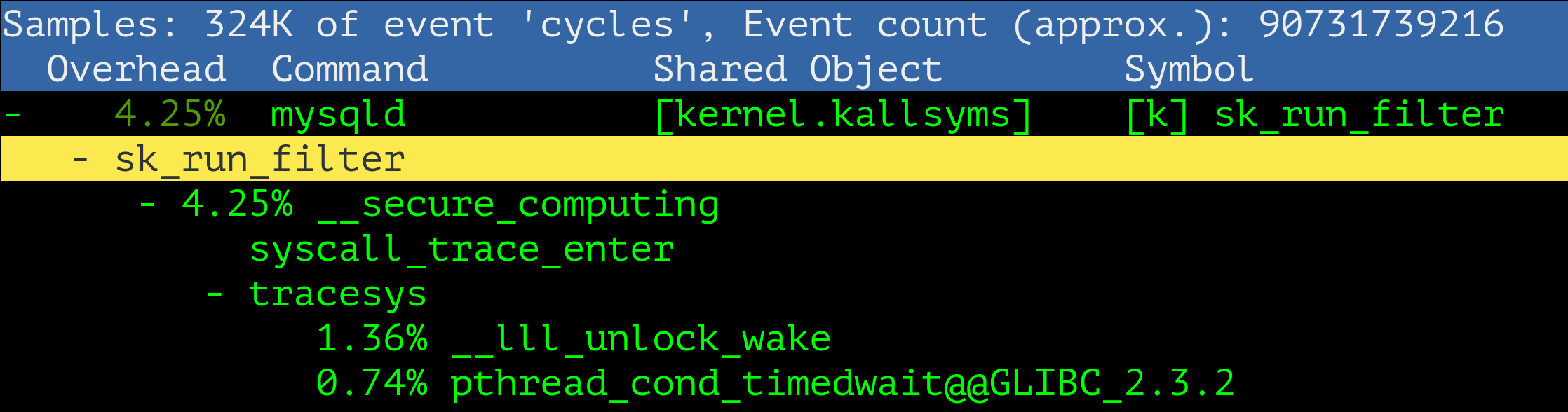
Let’s look for these symbols inside the Linux kernel 3.10 source code:
/**
* seccomp_run_filters - evaluates all seccomp filters against @syscall
* @syscall: number of the current system call
*
* Returns valid seccomp BPF response codes.
*/
static u32 seccomp_run_filters(int syscall)
{
struct seccomp_filter *f;
u32 ret = SECCOMP_RET_ALLOW;
/* Ensure unexpected behavior doesn't result in failing open. */
if (WARN_ON(current->seccomp.filter == NULL))
return SECCOMP_RET_KILL;
/*
* All filters in the list are evaluated and the lowest BPF return
* value always takes priority (ignoring the DATA).
*/
for (f = current->seccomp.filter; f; f = f->prev) {
u32 cur_ret = sk_run_filter(NULL, f->insns); // <<-- HERE
if ((cur_ret & SECCOMP_RET_ACTION) < (ret & SECCOMP_RET_ACTION))
ret = cur_ret;
}
return ret;
}
/* ... */
int __secure_computing(int this_syscall)
{
int mode = current->seccomp.mode;
int exit_sig = 0;
int *syscall;
u32 ret;
switch (mode) {
case SECCOMP_MODE_STRICT:
syscall = mode1_syscalls;
#ifdef CONFIG_COMPAT
if (is_compat_task())
syscall = mode1_syscalls_32;
#endif
do {
if (*syscall == this_syscall)
return 0;
} while (*++syscall);
exit_sig = SIGKILL;
ret = SECCOMP_RET_KILL;
break;
#ifdef CONFIG_SECCOMP_FILTER
case SECCOMP_MODE_FILTER: {
int data;
struct pt_regs *regs = task_pt_regs(current);
ret = seccomp_run_filters(this_syscall); // <<-- HERE
data = ret & SECCOMP_RET_DATA;
ret &= SECCOMP_RET_ACTION;
switch (ret) {
case SECCOMP_RET_ERRNO:
/* Set the low-order 16-bits as a errno. */
syscall_set_return_value(current, regs,
-data, 0);
goto skip;
/* ...... */
case SECCOMP_RET_ALLOW:
return 0;
case SECCOMP_RET_KILL:
default:
break;
}
exit_sig = SIGSYS;
break;
}
#endif
default:
BUG();
}
/* ...... */
}
/* ... */
static inline int secure_computing(int this_syscall)
{
if (unlikely(test_thread_flag(TIF_SECCOMP)))
return __secure_computing(this_syscall);
return 0;
}
The secure_computing for x86_64 platform can be found only in these two files:
- arch/x86/kernel/ptrace.c, let’s look deeper;
- arch/x86/kernel/vsyscall_64.c, not interesting: it serves only __NR_gettimeofday, __NR_time, __NR_getcpu in function emulate_vsyscall.
Let’s investigate arch/x86/kernel/ptrace.c
/*
* We must return the syscall number to actually look up in the table.
* This can be -1L to skip running any syscall at all.
*/
long syscall_trace_enter(struct pt_regs *regs)
{
long ret = 0;
user_exit();
/*
* If we stepped into a sysenter/syscall insn, it trapped in
* kernel mode; do_debug() cleared TF and set TIF_SINGLESTEP.
* If user-mode had set TF itself, then it's still clear from
* do_debug() and we need to set it again to restore the user
* state. If we entered on the slow path, TF was already set.
*/
if (test_thread_flag(TIF_SINGLESTEP))
regs->flags |= X86_EFLAGS_TF;
/* do the secure computing check first */
if (secure_computing(regs->orig_ax)) { // <<--- HERE
/* seccomp failures shouldn't expose any additional code. */
ret = -1L;
goto out;
}
/* ...... */
out:
return ret ?: regs->orig_ax;
}
/* ... */
/*
* Register setup:
* rax system call number
* rdi arg0
* rcx return address for syscall/sysret, C arg3
* rsi arg1
* rdx arg2
* r10 arg3 (--> moved to rcx for C)
* r8 arg4
* r9 arg5
* r11 eflags for syscall/sysret, temporary for C
* r12-r15,rbp,rbx saved by C code, not touched.
*
* Interrupts are off on entry.
* Only called from user space.
*
* XXX if we had a free scratch register we could save the RSP into the stack frame
* and report it properly in ps. Unfortunately we haven't.
*
* When user can change the frames always force IRET. That is because
* it deals with uncanonical addresses better. SYSRET has trouble
* with them due to bugs in both AMD and Intel CPUs.
*/
ENTRY(system_call)
/* .... a lot of assembler code .... */
/* Do syscall tracing */
tracesys:
#ifdef CONFIG_AUDITSYSCALL
testl $(_TIF_WORK_SYSCALL_ENTRY & ~_TIF_SYSCALL_AUDIT),TI_flags+THREAD_INFO(%rsp,RIP-ARGOFFSET)
jz auditsys
#endif
SAVE_REST
movq $-ENOSYS,RAX(%rsp) /* ptrace can change this for a bad syscall */
FIXUP_TOP_OF_STACK %rdi
movq %rsp,%rdi
call syscall_trace_enter // <<--- HERE
As we can see, the chain is following:
- system_call
- syscall_trace_enter
- secure_computing
- __secure_computing
- seccomp_run_filters
- sk_run_filter
Definitely this is what we are looking for!
Pay attention!!! The call is made directly to the sk_run_filter interpreter function, not to the JIT compiled bpf_func. So it hits the performance badly.
Now let’s compare the implementation of __secure_computing with the Linux kernel 4.19.
int __secure_computing(const struct seccomp_data *sd)
{
int mode = current->seccomp.mode;
int this_syscall;
if (IS_ENABLED(CONFIG_CHECKPOINT_RESTORE) &&
unlikely(current->ptrace & PT_SUSPEND_SECCOMP))
return 0;
this_syscall = sd ? sd->nr :
syscall_get_nr(current, task_pt_regs(current));
switch (mode) {
case SECCOMP_MODE_STRICT:
__secure_computing_strict(this_syscall); /* may call do_exit */
return 0;
case SECCOMP_MODE_FILTER:
return __seccomp_filter(this_syscall, sd, false); // <<-- HERE
/* Surviving SECCOMP_RET_KILL_* must be proactively impossible. */
case SECCOMP_MODE_DEAD:
WARN_ON_ONCE(1);
do_exit(SIGKILL);
return -1;
default:
BUG();
}
}
#ifdef CONFIG_SECCOMP_FILTER
static int __seccomp_filter(int this_syscall, const struct seccomp_data *sd,
const bool recheck_after_trace)
{
u32 filter_ret, action;
struct seccomp_filter *match = NULL;
int data;
/*
* Make sure that any changes to mode from another thread have
* been seen after TIF_SECCOMP was seen.
*/
rmb();
filter_ret = seccomp_run_filters(sd, &match); // <<-- HERE
/* ...... */
skip:
seccomp_log(this_syscall, 0, action, match ? match->log : false);
return -1;
}
/**
* seccomp_run_filters - evaluates all seccomp filters against @sd
* @sd: optional seccomp data to be passed to filters
* @match: stores struct seccomp_filter that resulted in the return value,
* unless filter returned SECCOMP_RET_ALLOW, in which case it will
* be unchanged.
*
* Returns valid seccomp BPF response codes.
*/
#define ACTION_ONLY(ret) ((s32)((ret) & (SECCOMP_RET_ACTION_FULL)))
static u32 seccomp_run_filters(const struct seccomp_data *sd,
struct seccomp_filter **match)
{
struct seccomp_data sd_local;
u32 ret = SECCOMP_RET_ALLOW;
/* Make sure cross-thread synced filter points somewhere sane. */
struct seccomp_filter *f =
READ_ONCE(current->seccomp.filter);
/* Ensure unexpected behavior doesn't result in failing open. */
if (unlikely(WARN_ON(f == NULL)))
return SECCOMP_RET_KILL_PROCESS;
if (!sd) {
populate_seccomp_data(&sd_local);
sd = &sd_local;
}
/*
* All filters in the list are evaluated and the lowest BPF return
* value always takes priority (ignoring the DATA).
*/
for (; f; f = f->prev) {
u32 cur_ret = BPF_PROG_RUN(f->prog, sd); // <<-- HERE
if (ACTION_ONLY(cur_ret) < ACTION_ONLY(ret)) {
ret = cur_ret;
*match = f;
}
}
return ret;
}
#endif /* CONFIG_SECCOMP_FILTER */
/* ...... */
struct sk_filter {
refcount_t refcnt;
struct rcu_head rcu;
struct bpf_prog *prog;
};
#define BPF_PROG_RUN(filter, ctx) (*(filter)->bpf_func)(ctx, (filter)->insnsi)
Pay attention!!! In Linux kernel 4.19 the seccomp is powered by JIT - the bpf_func is invoked.
Seccomp in Docker
The docker-engine provides the seccomp feature. Look into the official docker documentation for more details. Moreover, the Openstack host machine usually has the following JSON file which overrides the docker seccomp defaults (anyway, it doesn’t matter too much, because the defaults from docker or Openstack contains the whitelist of about 300+ system calls allowed for the container):
{
"defaultAction": "SCMP_ACT_ERRNO",
"architectures": [
"SCMP_ARCH_X86_64",
"SCMP_ARCH_X86",
"SCMP_ARCH_X32"
],
"syscalls": [
{
"name": "io_submit",
"action": "SCMP_ACT_ALLOW",
"priority": 254
},
# for each allowed system call there's an entry here => 300+ entries #
]
}
Note: for our research we’ve got the default JSON configuration files (from Docker and Openstack), your production configuration might be different.
The docker might upload BPF program to the Linux kernel using either prctl (older kernels) or seccomp (recent) system calls, look at the docker’s runc component (libcontainer/seccomp/patchbpf/enosys_linux.go)
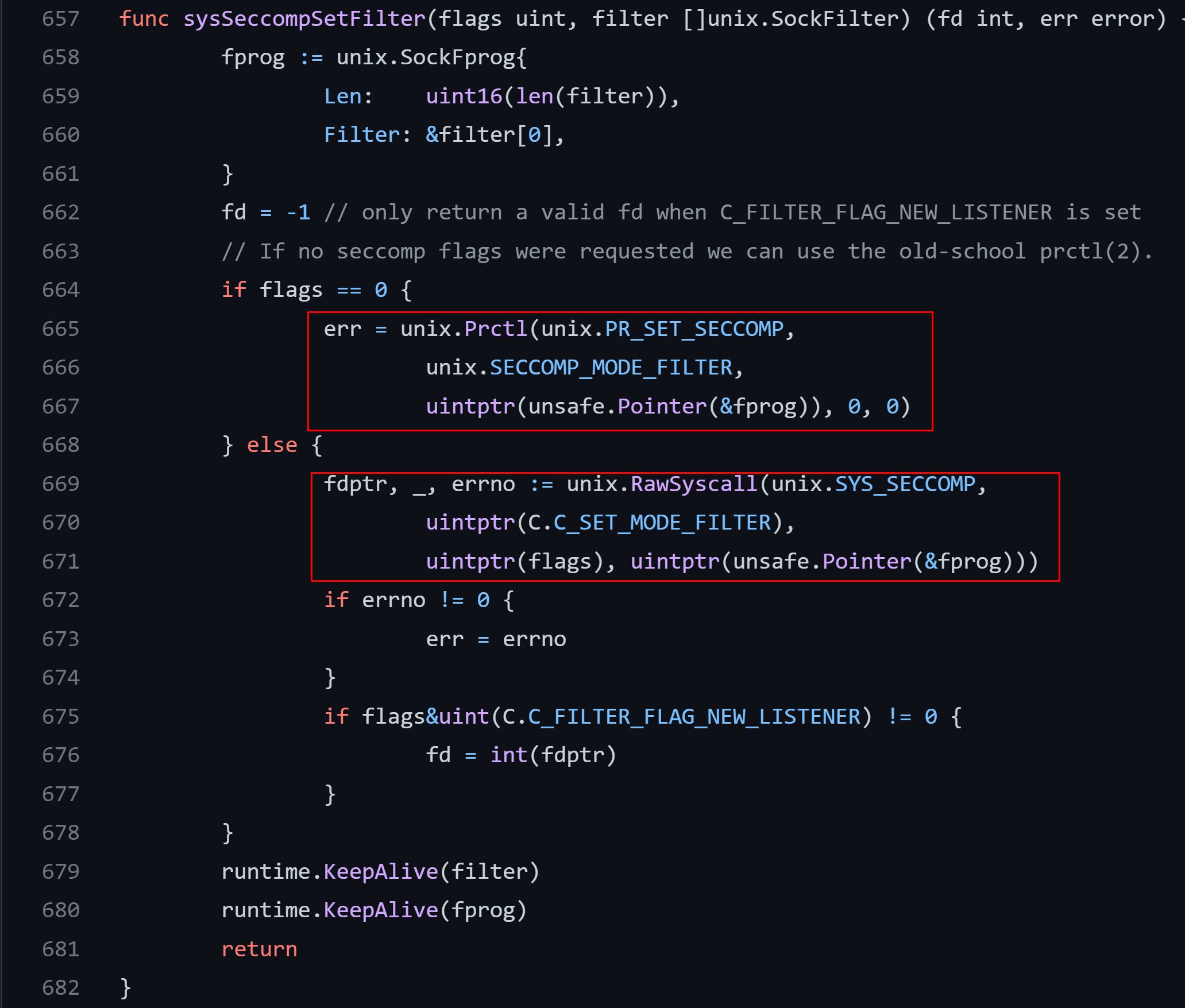
The BPF program is constructed on the fly from the JSON file, the following snippets of the code proves it:
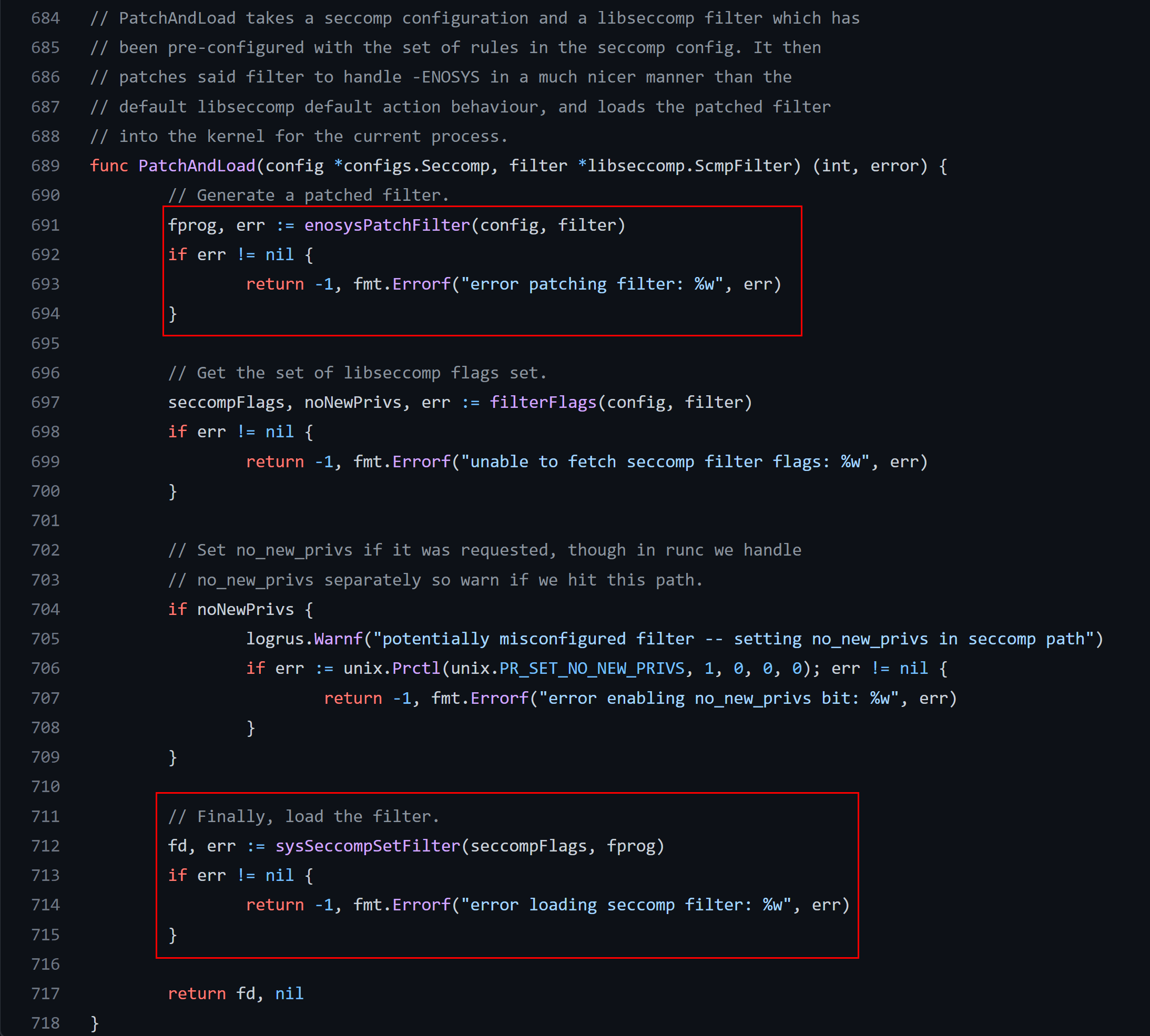
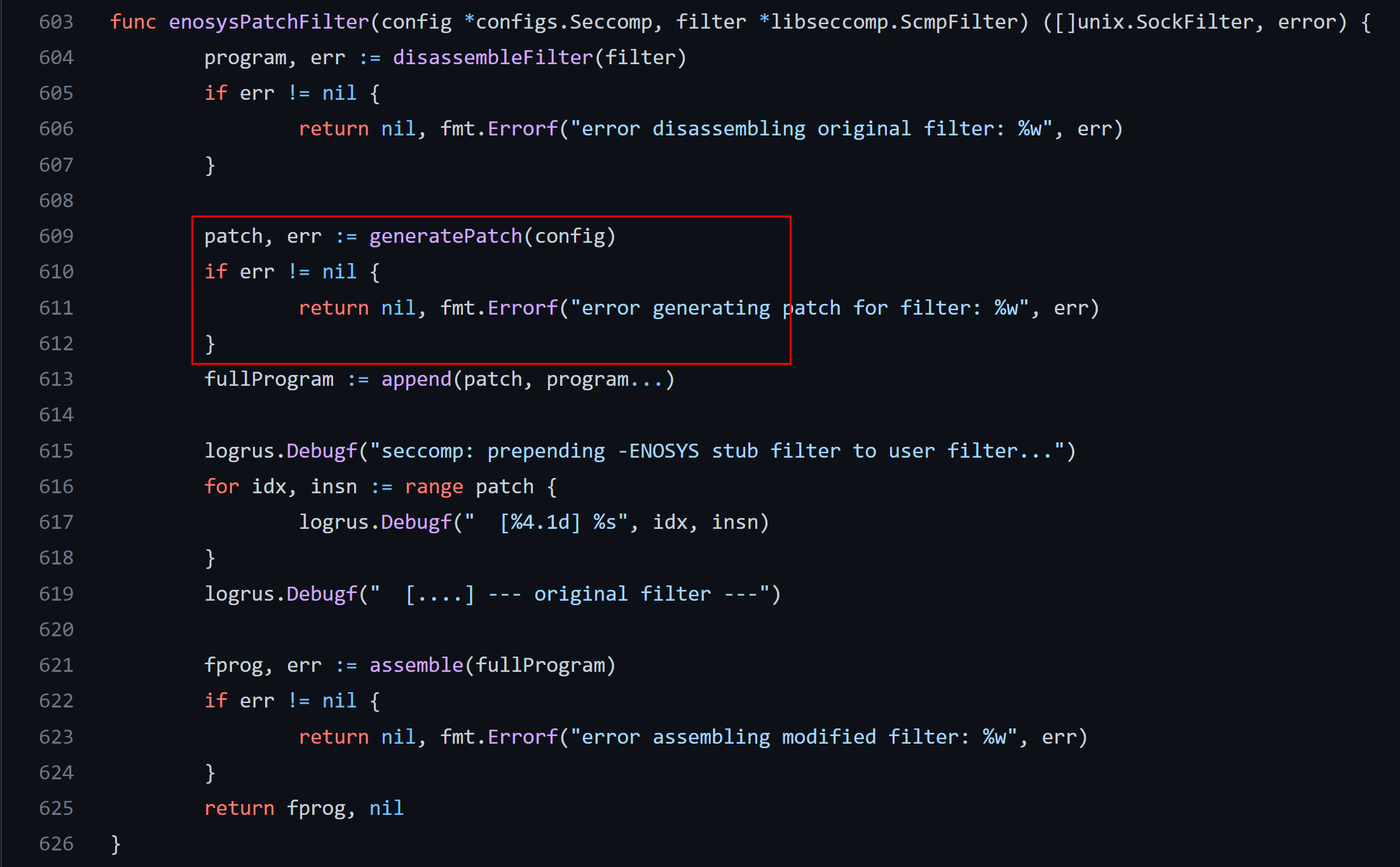
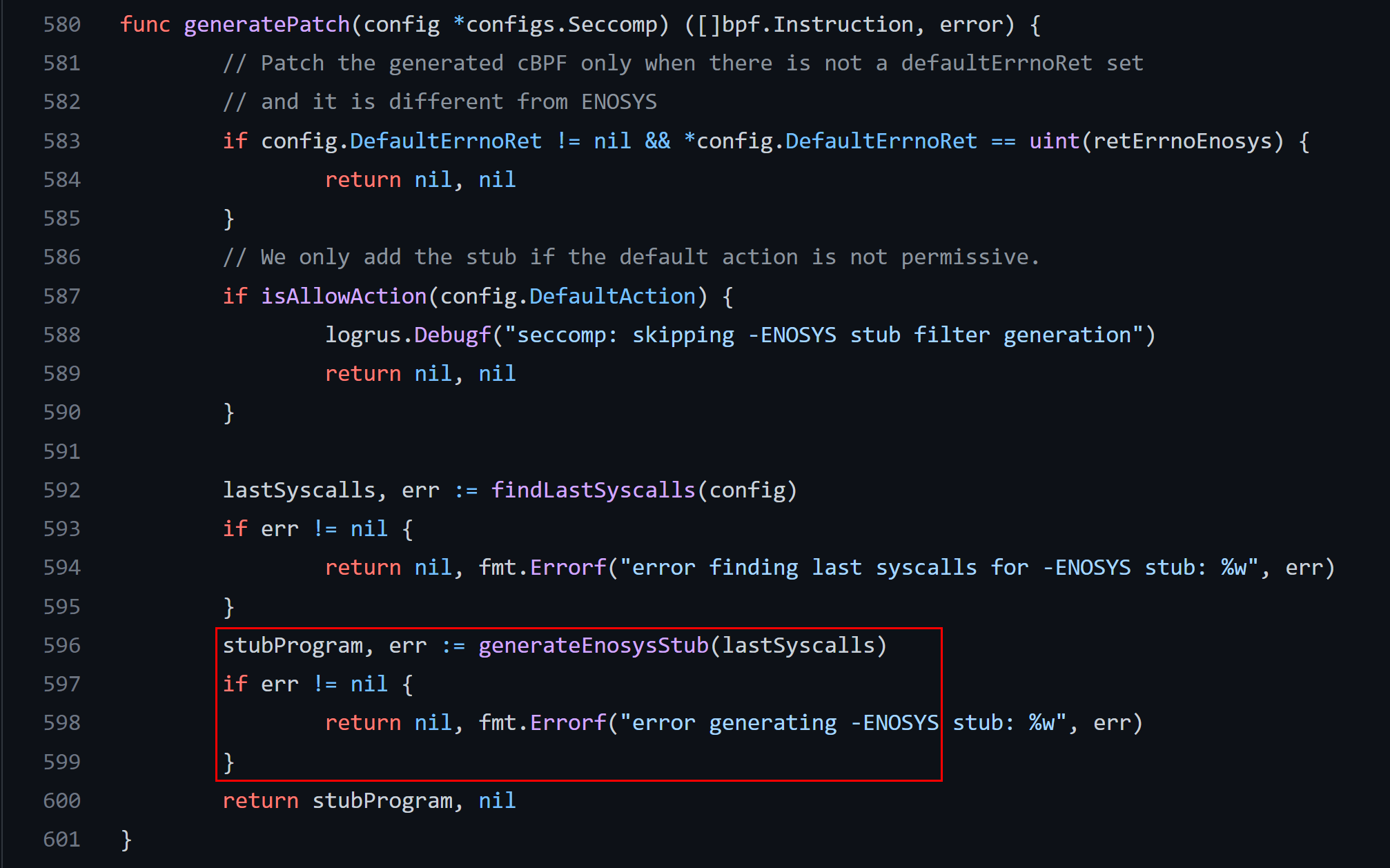
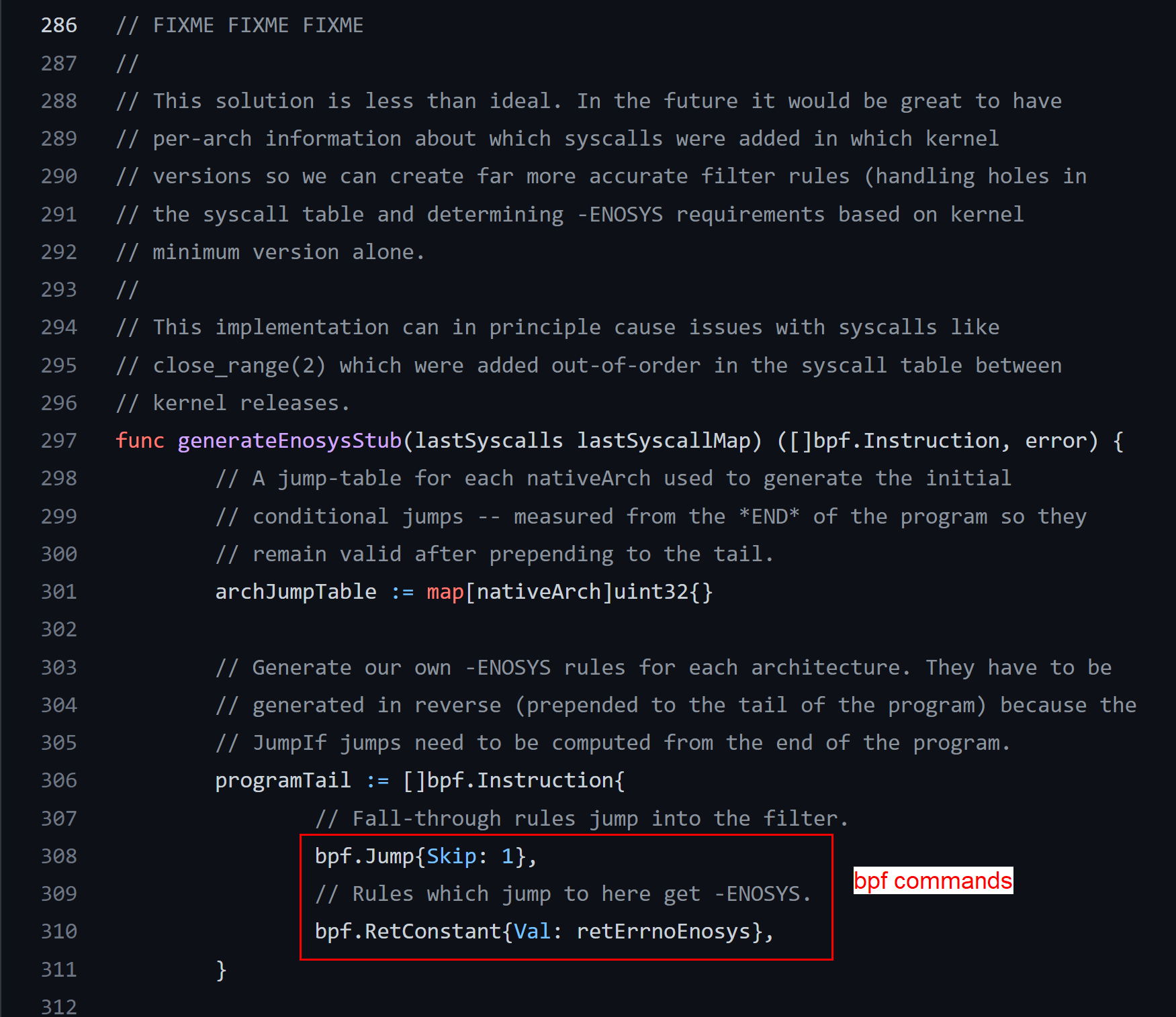
The BPF commands are packed in the C-struct which resembles the kernel structure sock_filter:
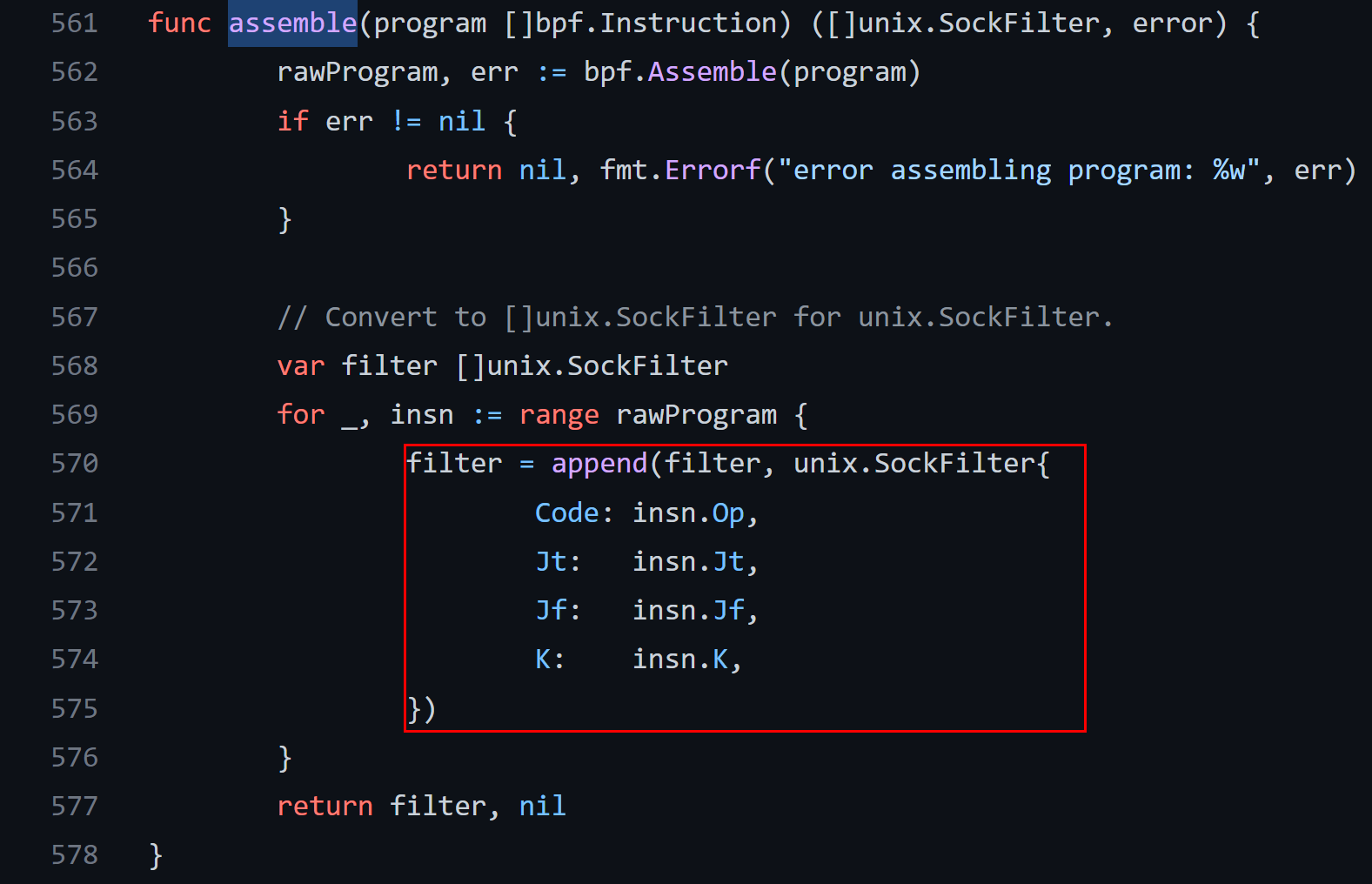
/*
* Try and keep these values and structures similar to BSD, especially
* the BPF code definitions which need to match so you can share filters
*/
struct sock_filter { /* Filter block */
__u16 code; /* Actual filter code */
__u8 jt; /* Jump true */
__u8 jf; /* Jump false */
__u32 k; /* Generic multiuse field */
};
struct sock_fprog { /* Required for SO_ATTACH_FILTER. */
unsigned short len; /* Number of filter blocks */
struct sock_filter __user *filter;
};
Reproducing the problem
As a small reproducer the pthread_cond_timedwait system call was chosen, since our MySQL server invokes it quite often. The testing code creates some threads which make very frequent calls to pthread_cond_timedwait:
#include <pthread.h>
#include <stdio.h>
#include <time.h>
#include <unistd.h>
pthread_mutex_t MUX;
pthread_cond_t COND;
int finish = 0;
#define TH_NUM 256
#define NSEC 1000
pthread_t TH[TH_NUM];
void* thread_func(void *arg) {
struct timespec ts;
pthread_mutex_lock(&MUX);
while(!finish) {
clock_gettime(CLOCK_REALTIME, &ts);
ts.tv_nsec += NSEC;
pthread_cond_timedwait(&COND, &MUX, &ts);
}
pthread_mutex_unlock(&MUX);
printf("Finished\n");
return NULL;
}
int main() {
pthread_mutex_init(&MUX, NULL);
pthread_cond_init(&COND, NULL);
for (int i=0; i<TH_NUM; ++i)
pthread_create(&TH[i], NULL, thread_func, NULL);
pause();
pthread_mutex_lock(&MUX);
finish = 0;
pthread_mutex_unlock(&MUX);
pthread_cond_broadcast(&COND);
return 0;
}
Our steps:
- copy our docker’s default JSON file (
seccomp.json) to a local server, - run the docker engine using
--security-opt seccomp:seccomp.json, - compile the small reproducer (
inf.c, published right ahead), - gather the perf profile,
- using Linux kernel 3.10
[host]$ gcc --version
gcc (GCC) 10.3.0
[host]$ gcc inf.c -o inf -pthread
[host]$ docker run --security-opt seccomp:$HOME/sk_run_filter/seccomp.json -v$HOME:$HOME -it $euler_os_container /bin/bash
[container]$ cd $HOME/sk_run_filter/
[container]$ ./inf
[host]$ ps aux | grep './inf'
root 54628 401 0.0 2104832 2496 pts/0 Sl+ 21:40 2:20 ./inf
root 59153 0.0 0.0 112672 952 pts/52 S+ 21:40 0:00 grep --color=auto ./inf
[host]$ perf record -p 54628 -- sleep 10
[ perf record: Woken up 33 times to write data ]
[ perf record: Captured and wrote 12.998 MB perf.data (335688 samples) ]
[host]$ perf report


Aga! sk_run_filter showed his true face! Repeat the same steps for the Linux kernel 4.19.


As we can see, the bottleneck in Linux 4.19 shifted to the do_syscall_64, no more sk_run_filter or __secure_computing.
Mitigation for the Linux kernel 3.10
If you look into the Linux kernel 3.10 arch/x86/syscalls/syscall_64.tbl, you will see 313 system calls for x86_64 architecture.
#
# 64-bit system call numbers and entry vectors
#
# The format is:
# <number> <abi> <name> <entry point>
#
# The abi is "common", "64" or "x32" for this file.
#
0 common read sys_read
1 common write sys_write
2 common open sys_open
3 common close sys_close
......
310 64 process_vm_readv sys_process_vm_readv
311 64 process_vm_writev sys_process_vm_writev
312 common kcmp sys_kcmp
313 common finit_module sys_finit_module
Analyzing our local JSON file and the list of all available system calls, we can conclude that the amount of allowed system calls is roughly 300, while the amount of filtered out - about 40 (the default JSON file might contain system calls for a wide range of Linux kernels: for example, from 3.10 to 5.15, that’s why 300+40 != 313). So, blocking 40+ calls looks better, let’s try.
my.json file:
{
"defaultAction": "SCMP_ACT_ALLOW",
"architectures": [
"SCMP_ARCH_X86_64"
],
"syscalls": [
{"name":"acct", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"add_key", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"adjtimex", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"afs_syscall", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"clock_adjtime", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"clock_settime", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"create_module", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"delete_module", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"finit_module", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"get_kernel_syms", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"get_mempolicy", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"getpmsg", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"init_module", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"ioperm", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"iopl", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"kcmp", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"kexec_load", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"keyctl", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"mbind", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"migrate_pages", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"mlock", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"mlockall", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"move_pages", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"nfsservctl", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"open_by_handle_at", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"pivot_root", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"process_vm_readv", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"process_vm_writev", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"ptrace", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"putpmsg", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"query_module", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"quotactl", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"request_key", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"security", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"set_mempolicy", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"settimeofday", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"swapoff", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"swapon", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"_sysctl", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"sysfs", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"tuxcall", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"uselib", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"ustat", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"vhangup", "action":"SCMP_ACT_ERRNO", "priority":1},
{"name":"vserver", "action":"SCMP_ACT_ERRNO", "priority":1}
]
}
Evaluating under our small reproducer:
[host]$ docker run --security-opt seccomp:$HOME/sk_run_filter/my.json -v$HOME:$HOME -it $euler_os_container /bin/bash
[container]$ ./inf
[host]$ ps aux | grep './inf'
root 45259 325 0.0 2104832 2496 pts/0 Sl+ 22:02 0:26 ./inf
root 46403 0.0 0.0 112668 952 pts/52 S+ 22:02 0:00 grep --color=auto ./inf
[host]$ perf record -p 45259 -- sleep 10
[ perf record: Woken up 23 times to write data ]
[ perf record: Captured and wrote 11.160 MB perf.data (287512 samples) ]
[host]$ perf report


CPU usage drops from 50% to 20%, not that bad for the first try. Meanwhile the question which doesn’t give piece to my mind is what inside the generated BPF program and why it takes so long to execute it?
Evaluation of BPF program generated by docker
BPF program is stored in the (task_struct*)current->seccomp.filter:
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace;
#ifdef CONFIG_SMP
struct llist_node wake_entry;
int on_cpu;
#endif
/* .... a lot of fields .... */
struct seccomp seccomp; //<<-- HERE
/* .... */
};
/* ... */
/**
* struct seccomp - the state of a seccomp'ed process
*
* @mode: indicates one of the valid values above for controlled
* system calls available to a process.
* @filter: The metadata and ruleset for determining what system calls
* are allowed for a task.
*
* @filter must only be accessed from the context of current as there
* is no locking.
*/
struct seccomp {
int mode;
struct seccomp_filter *filter;
};
/* ... */
/**
* struct seccomp_filter - container for seccomp BPF programs
*
* @usage: reference count to manage the object lifetime.
* get/put helpers should be used when accessing an instance
* outside of a lifetime-guarded section. In general, this
* is only needed for handling filters shared across tasks.
* @prev: points to a previously installed, or inherited, filter
* @len: the number of instructions in the program
* @insns: the BPF program instructions to evaluate
*
* seccomp_filter objects are organized in a tree linked via the @prev
* pointer. For any task, it appears to be a singly-linked list starting
* with current->seccomp.filter, the most recently attached or inherited filter.
* However, multiple filters may share a @prev node, by way of fork(), which
* results in a unidirectional tree existing in memory. This is similar to
* how namespaces work.
*
* seccomp_filter objects should never be modified after being attached
* to a task_struct (other than @usage).
*/
struct seccomp_filter {
atomic_t usage;
struct seccomp_filter *prev;
unsigned short len; /* Instruction count */
struct sock_filter insns[];
};
The BPF program itself is stored in seccomp_filter::insns and the instructions count - in seccomp::len. Let’s evaluate the size of BPF program generated from our Openstack default docker’s seccomp JSON file. To achieve this task, we need to get the access to the current task task_struct, so it’s required to switch to the kernel space. Let’s create a very simple kernel module which serves the character device. As a working example this blog was used.
Module source code:
#include <asm/uaccess.h>
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/fs.h>
#include <linux/sched.h>
#include <uapi/linux/filter.h>
struct seccomp_filter {
atomic_t usage;
struct seccomp_filter *prev;
unsigned short len; /* Instruction count */
struct sock_filter insns[];
};
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Philimonov Dmitriy");
MODULE_DESCRIPTION("Getting the seccomp instructions count");
MODULE_VERSION("0.01");
#define DEVICE_NAME "seccomp_icount"
/* Prototypes for device functions */
static int device_open(struct inode *, struct file *);
static int device_release(struct inode *, struct file *);
static ssize_t device_read(struct file *, char *, size_t, loff_t *);
static ssize_t device_write(struct file *, const char *, size_t, loff_t *);
static int major_num;
static int device_open_count = 0;
unsigned long get_seccomp_icount(void) {
struct seccomp_filter *f;
unsigned long commands_count = 0;
for (f = current->seccomp.filter; f; f = f->prev) {
commands_count += f->len;
}
printk(KERN_INFO "Servicing the process pid=%d, seccomp_mode=%d, seccomp_filter=%p, instructions=%lu\n",
current->pid,
current->seccomp.mode,
current->seccomp.filter,
commands_count);
return commands_count;
}
/* This structure points to all of the device functions */
static struct file_operations file_ops = {
.read = device_read,
.write = device_write,
.open = device_open,
.release = device_release
};
/* When a process reads from our device, this gets called. */
static ssize_t device_read(struct file *flip, char *buffer, size_t len, loff_t *offset) {
char kbuf[32];
size_t bytes_written, copied;
if (*offset > 0)
return 0;
bytes_written = scnprintf(kbuf, 32, "%lu\n", get_seccomp_icount());
copied = bytes_written <= len ? bytes_written : len;
if (copy_to_user(buffer, kbuf, copied))
return 0;
*offset += copied;
return copied;
}
/* Called when a process tries to write to our device */
static ssize_t device_write(struct file *flip, const char *buffer, size_t len, loff_t *offset) {
/* This is a read-only device */
printk(KERN_ALERT "This operation is not supported.\n");
return -EINVAL;
}
/* Called when a process opens our device */
static int device_open(struct inode *inode, struct file *file) {
/* If device is open, return busy */
if (device_open_count) {
return -EBUSY;
}
device_open_count++;
try_module_get(THIS_MODULE);
return 0;
}
/* Called when a process closes our device */
static int device_release(struct inode *inode, struct file *file) {
/* Decrement the open counter and usage count. Without this, the module would not unload. */
device_open_count--;
module_put(THIS_MODULE);
return 0;
}
static int __init seccomp_icount_init(void) {
/* Try to register character device */
major_num = register_chrdev(0, DEVICE_NAME, &file_ops);
if (major_num < 0) {
printk(KERN_ALERT "Could not register device: %d\n", major_num);
return major_num;
} else {
printk(KERN_INFO "seccomp_icount module loaded with device major number %d\n", major_num);
return 0;
}
}
static void __exit seccomp_icount_exit(void) {
/* Remember — we have to clean up after ourselves. Unregister the character device. */
unregister_chrdev(major_num, DEVICE_NAME);
printk(KERN_INFO "Unregistering seccomp_icount\n");
}
/* Register module functions */
module_init(seccomp_icount_init);
module_exit(seccomp_icount_exit);
A Makefile for it:
obj-m += seccomp_icount.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
Next steps:
- Compile the module for the Linux kernel 3.10
- Insert module into the running kernel
- Create a character device
- Run docker container with the custom seccomp enabled, propagate the custom device to the container
- Check the amount of BPF instructions which is executed each system call
[host]$ gcc --version
gcc (GCC) 4.8.5 20150623 (EulerOS 4.8.5-4)
[host]$ cd k310.module && make
[host]$ dmesg -C # clear debug ring buffer
[host]$ insmod seccomp_icount.ko
[host]$ dmesg -T
seccomp_icount module loaded with device major number 241
[host]$ MAJOR=241; sudo mknod /dev/seccomp_icount c $MAJOR 0
[host]$ docker run --security-opt seccomp:$HOME/sk_run_filter/seccomp.json -v$HOME:$HOME --device=/dev/seccomp_icount:/dev/seccomp_icount -it $euler_os_container /bin/bash
[container]$ cat /dev/seccomp_icount
953
[host]$ dmesg | tail -n1
Servicing the process pid=19032, seccomp_mode=2, seccomp_filter=ffff88013721c000, instructions=953
So, the docker-engine::runc creates the program with about 953 instructions in our case, which are interpreted each system call made by all programs inside docker container including MySQL server.
Using blacklist mitigation (smaller seccomp JSON file):
[host]$ docker run --security-opt seccomp:$HOME/sk_run_filter/my.json -v$HOME:$HOME --device=/dev/seccomp_icount:/dev/seccomp_icount -it $euler_os_container /bin/bash
[container]$ cat /dev/seccomp_icount
52
[host]$ dmesg -T
Servicing the process pid=42143, seccomp_mode=2, seccomp_filter=ffff8847e525ca00, instructions=52
So, the amount of BPF instructions are reduced from 953 to 52.
Impact on our MySQL server
According to my benchmarks, the performance drop for our MySQL server is huge: more than 40%. Some benchmark results for 1u4g cloud instance, configured with CFS quota, data set is 40 tables, 10 millions rows each:
| Load type | Threads | Performance drop |
|---|---|---|
| OLTP_PS | 8 | -46.06% |
| OLTP_RO | 8 | -41.76% |
| OLTP_RW | 1 | -24.54% |
| OLTP_UPDATE_INDEX | 1 | -15.98% |
| OLTP_UPDATE_NON_INDEX | 64 | -38.48% |
The CPU waste (per load type):
| OLTP | CPU kernel 3.10 | CPU kernel 4.18 |
|---|---|---|
| PS/64 | 23.62% | 0.03% |
| RO/64 | 19.35% | 0.02% |
| RW/64 | 17.90% | 0.02% |
| WO/64 | 21.56% | 0.05% |
| UPDATE_INDEX/64 | 22.45% | 0.03% |
| UPDATE_NON_INDEX/64 | 29.93% | 0.04% |
| INSERT/64 | 16.80% | 0.05% |
Why the execution of BPF program is so sub-optimal?
Let’s dump the BPF code from the kernel space. We need to modify our simple kernel module a bit for it (dump the current->seccomp.filter.insns):
#include <linux/uaccess.h>
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/fs.h>
#include <linux/sched.h>
#include <uapi/linux/filter.h>
struct seccomp_filter {
atomic_t usage;
struct seccomp_filter *prev;
unsigned short len; /* Instruction count */
struct sock_filter insns[];
};
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Philimonov Dmitriy");
MODULE_DESCRIPTION("Dumping the seccomp instructions for kernel 3.10");
MODULE_VERSION("0.01");
#define DEVICE_NAME "seccomp_idump"
/* Prototypes for device functions */
static int device_open(struct inode *, struct file *);
static int device_release(struct inode *, struct file *);
static ssize_t device_read(struct file *, char *, size_t, loff_t *);
static ssize_t device_write(struct file *, const char *, size_t, loff_t *);
static int major_num;
static int device_open_count = 0;
void print_seccomp_icount(void) {
struct seccomp_filter *f;
unsigned long commands_count = 0;
for (f = current->seccomp.filter; f; f = f->prev) {
commands_count += f->len;
}
printk(KERN_INFO "Servicing the process pid=%d, seccomp_mode=%d, seccomp_filter=%p, instructions=%lu\n",
current->pid,
current->seccomp.mode,
current->seccomp.filter,
commands_count);
}
/* This structure points to all of the device functions */
static struct file_operations file_ops = {
.read = device_read,
.write = device_write,
.open = device_open,
.release = device_release
};
/* When a process reads from our device, this gets called. */
static ssize_t device_read(struct file *flip, char *buffer, size_t len, loff_t *offset) {
size_t fp_size, left, copied, curr_offset = *offset;
struct seccomp_filter *fprog = current->seccomp.filter;
if (!fprog)
return 0;
fp_size = fprog->len * sizeof(struct sock_filter);
if (curr_offset > fp_size)
return 0;
left = fp_size - curr_offset;
copied = min(left, len);
printk(KERN_INFO "Servicing device_read: fprog=%p, fp_size=%lu, offset=%lu, left=%lu, len=%lu\n",
fprog, fp_size, curr_offset, left, len);
if (!copied || copy_to_user(buffer, (char *)(fprog->insns) + curr_offset, copied))
return 0;
curr_offset += copied;
*offset = curr_offset;
return copied;
}
/* Called when a process tries to write to our device */
static ssize_t device_write(struct file *flip, const char *buffer, size_t len, loff_t *offset) {
/* This is a read-only device */
printk(KERN_ALERT "This operation is not supported.\n");
return -EINVAL;
}
/* Called when a process opens our device */
static int device_open(struct inode *inode, struct file *file) {
/* If device is open, return busy */
if (device_open_count) {
return -EBUSY;
}
device_open_count++;
print_seccomp_icount();
try_module_get(THIS_MODULE);
return 0;
}
/* Called when a process closes our device */
static int device_release(struct inode *inode, struct file *file) {
/* Decrement the open counter and usage count. Without this, the module would not unload. */
device_open_count--;
module_put(THIS_MODULE);
return 0;
}
static int __init seccomp_idump_init(void) {
/* Try to register character device */
major_num = register_chrdev(0, DEVICE_NAME, &file_ops);
if (major_num < 0) {
printk(KERN_ALERT "Could not register device: %d\n", major_num);
return major_num;
} else {
printk(KERN_INFO "seccomp_idump module loaded with device major number %d\n", major_num);
return 0;
}
}
static void __exit seccomp_idump_exit(void) {
/* Remember — we have to clean up after ourselves. Unregister the character device. */
unregister_chrdev(major_num, DEVICE_NAME);
printk(KERN_INFO "Unregistering seccomp_idump\n");
}
/* Register module functions */
module_init(seccomp_idump_init);
module_exit(seccomp_idump_exit);
Now we can do the same magic as before:
[host]$ cd k310.idump && make && insmod seccomp_idump.ko
[host]$ dmesg -T
seccomp_idump module loaded with device major number 237
[host]$ MAJOR=237; sudo mknod /dev/seccomp_idump c $MAJOR 0
[host]$ docker run --security-opt seccomp:$HOME/sk_run_filter/seccomp.json -v$HOME:$HOME --device=/dev/seccomp_idump:/dev/seccomp_idump -it $euler_os_container /bin/bash
[container]$ cat /dev/seccomp_idump > BPF.code
[host]$ dmesg | tail
Servicing the process pid=32557, seccomp_mode=2, seccomp_filter=ffff9ada124c0000, instructions=959
Servicing device_read: fprog=ffff9ada124c0000, fp_size=7672, offset=0, left=7672, len=65536
Servicing device_read: fprog=ffff9ada124c0000, fp_size=7672, offset=7672, left=0, len=65536
Note: I used a different server/docker, and the amount of instructions changed (953 -> 959), while the JSON file stayed the same.
Now we need to write a simple disassembler for the BPF code, which was just dumped. Using the sources from Linux kernel 3.10 we have something like this:
#include <stdio.h>
#include <stdint.h>
struct sock_filter { /* Filter block */
uint16_t code; /* Actual filter code */
uint8_t jt; /* Jump true */
uint8_t jf; /* Jump false */
uint32_t k; /* Generic multiuse field */
};
using sock_filter_t = struct sock_filter;
const char* disassemble_code(const uint16_t code) {
static const char *code2str[] {
" #0 ",
"BPF_S_RET_K ",
"BPF_S_RET_A ",
"BPF_S_ALU_ADD_K ",
"BPF_S_ALU_ADD_X ",
"BPF_S_ALU_SUB_K ",
"BPF_S_ALU_SUB_X ",
"BPF_S_ALU_MUL_K ",
"BPF_S_ALU_MUL_X ",
"BPF_S_ALU_DIV_X ",
"BPF_S_ALU_MOD_K ",
"BPF_S_ALU_MOD_X ",
"BPF_S_ALU_AND_K ",
"BPF_S_ALU_AND_X ",
"BPF_S_ALU_OR_K ",
"BPF_S_ALU_OR_X ",
"BPF_S_ALU_XOR_K ",
"BPF_S_ALU_XOR_X ",
"BPF_S_ALU_LSH_K ",
"BPF_S_ALU_LSH_X ",
"BPF_S_ALU_RSH_K ",
"BPF_S_ALU_RSH_X ",
"BPF_S_ALU_NEG ",
"BPF_S_LD_W_ABS ",
"BPF_S_LD_H_ABS ",
"BPF_S_LD_B_ABS ",
"BPF_S_LD_W_LEN ",
"BPF_S_LD_W_IND ",
"BPF_S_LD_H_IND ",
"BPF_S_LD_B_IND ",
"BPF_S_LD_IMM ",
"BPF_S_LDX_W_LEN ",
"BPF_S_LDX_B_MSH ",
"BPF_S_LDX_IMM ",
"BPF_S_MISC_TAX ",
"BPF_S_MISC_TXA ",
"BPF_S_ALU_DIV_K ",
"BPF_S_LD_MEM ",
"BPF_S_LDX_MEM ",
"BPF_S_ST ",
"BPF_S_STX ",
"BPF_S_JMP_JA ",
"BPF_S_JMP_JEQ_K ",
"BPF_S_JMP_JEQ_X ",
"BPF_S_JMP_JGE_K ",
"BPF_S_JMP_JGE_X ",
"BPF_S_JMP_JGT_K ",
"BPF_S_JMP_JGT_X ",
"BPF_S_JMP_JSET_K ",
"BPF_S_JMP_JSET_X ",
"BPF_S_ANC_PROTOCOL ",
"BPF_S_ANC_PKTTYPE ",
"BPF_S_ANC_IFINDEX ",
"BPF_S_ANC_NLATTR ",
"BPF_S_ANC_NLATTR_NEST ",
"BPF_S_ANC_MARK ",
"BPF_S_ANC_QUEUE ",
"BPF_S_ANC_HATYPE ",
"BPF_S_ANC_RXHASH ",
"BPF_S_ANC_CPU ",
"BPF_S_ANC_ALU_XOR_X ",
"BPF_S_ANC_SECCOMP_LD_W ",
"BPF_S_ANC_VLAN_TAG ",
"BPF_S_ANC_VLAN_TAG_PRESENT",
"BPF_S_ANC_PAY_OFFSET ",
};
static const char *error="???";
if (code >= sizeof(code2str)/sizeof(const char*))
return error;
return code2str[code];
}
void disassemble(const sock_filter_t *f) {
disassemble_code(f->code);
printf("%s 0x%04x jt=0x%02x jf=0x%02x k=0x%08x\n",
disassemble_code(f->code), f->code, f->jt, f->jf, f->k
);
}
#define BUF_SIZE 512
sock_filter_t buffer[BUF_SIZE];
int main(int argc, char **argv) {
FILE *ifile = stdin;
if (argc >= 2) {
const char *ifilename = argv[1];
ifile = fopen(ifilename, "r");
}
size_t total_processed = 0;
while(size_t items = fread(&buffer, sizeof(sock_filter_t), BUF_SIZE, ifile)) {
for (size_t i = 0; i < items; ++i)
disassemble(buffer + i);
total_processed += items;
}
if (ifile != stdin) fclose(ifile);
printf(
"=======================================================\n"
"Processed instructions: %lu\n", total_processed
);
return 0;
}
So, what is inside?
[host]$ ./dbpf BPF.code
BPF_S_ANC_SECCOMP_LD_W 0x003d jt=0x00 jf=0x00 k=0x00000004
BPF_S_JMP_JEQ_K 0x002a jt=0x01 jf=0x00 k=0xc000003e
BPF_S_JMP_JA 0x0029 jt=0x00 jf=0x00 k=0x00000285
BPF_S_ANC_SECCOMP_LD_W 0x003d jt=0x00 jf=0x00 k=0x00000000
BPF_S_JMP_JEQ_K 0x002a jt=0xb5 jf=0x00 k=0x00000000
BPF_S_JMP_JEQ_K 0x002a jt=0xb4 jf=0x00 k=0x00000001
BPF_S_JMP_JEQ_K 0x002a jt=0xb3 jf=0x00 k=0x00000002
BPF_S_JMP_JEQ_K 0x002a jt=0xb2 jf=0x00 k=0x00000003
BPF_S_JMP_JEQ_K 0x002a jt=0xb1 jf=0x00 k=0x00000004
BPF_S_JMP_JEQ_K 0x002a jt=0xb0 jf=0x00 k=0x00000005
BPF_S_JMP_JEQ_K 0x002a jt=0xaf jf=0x00 k=0x00000006
BPF_S_JMP_JEQ_K 0x002a jt=0xae jf=0x00 k=0x00000007
BPF_S_JMP_JEQ_K 0x002a jt=0xad jf=0x00 k=0x00000008
...
BPF_S_JMP_JEQ_K 0x002a jt=0x08 jf=0x00 k=0x00000174
BPF_S_JMP_JEQ_K 0x002a jt=0x07 jf=0x00 k=0x00000175
BPF_S_JMP_JEQ_K 0x002a jt=0x06 jf=0x00 k=0x00000179
BPF_S_JMP_JEQ_K 0x002a jt=0x00 jf=0x04 k=0x00000088
BPF_S_ANC_SECCOMP_LD_W 0x003d jt=0x00 jf=0x00 k=0x00000010
BPF_S_JMP_JEQ_K 0x002a jt=0x03 jf=0x00 k=0xffffffff
BPF_S_JMP_JEQ_K 0x002a jt=0x02 jf=0x00 k=0x00000008
BPF_S_JMP_JEQ_K 0x002a jt=0x01 jf=0x00 k=0x00000000
BPF_S_RET_K 0x0001 jt=0x00 jf=0x00 k=0x00050001
BPF_S_RET_K 0x0001 jt=0x00 jf=0x00 k=0x7fff0000
BPF_S_RET_K 0x0001 jt=0x00 jf=0x00 k=0x00000000
=======================================================
Processed instructions: 959
The pattern shown above repeats 3 times - for each of 3 architectures specified in the original JSON file (“SCMP_ARCH_X86_64”, “SCMP_ARCH_X86” and “SCMP_ARCH_X32”), eventually there’s roughly 300 * 3 = 900, which matches the amount of system calls for Linux kernel 3.10 (313). Let’s try to read this assembler. The input for the BPF program is that structure:
/**
* struct seccomp_data - the format the BPF program executes over.
* @nr: the system call number
* @arch: indicates system call convention as an AUDIT_ARCH_* value
* as defined in <linux/audit.h>.
* @instruction_pointer: at the time of the system call.
* @args: up to 6 system call arguments always stored as 64-bit values
* regardless of the architecture.
*/
struct seccomp_data {
int nr;
__u32 arch;
__u64 instruction_pointer;
__u64 args[6];
};
So, the first instruction BPF_S_ANC_SECCOMP_LD_W reads the arch field (offset 4), then checks for the value 0xc000003e (x86_64). If true jump +1 instruction from the current position, so we execute the second BPF_S_ANC_SECCOMP_LD_W instruction, which reads the syscall number (offset 0, field nr). Then there’s the long chain of BPF_S_JMP_JEQ_K instructions which check that syscall number with the constants 0x1, 0x2, 0x3, 0x4 … and so on (field k). If comparison succeeds the jump is done (shift is stored in jt field of the instruction), otherwise the next instruction is executed in the chain. Eventually, we have the code like this:
A = seccomp_data.arch;
if (A != x86_64) goto other_arch;
A = seccomp_data.nr # syscall_number
if (A == 1) then goto allow-label;
if (A == 2) then goto allow-lalel;
if (A == 3) then goto allow-label;
if (A == 4) then goto allow-label;
...
if (A == 300) then goto allow-label;
error-label: return error-code;
allow-label: return allow-code;
other_arch: <repeat the code pattern again>
As you can see, this is O(n) algorithm, which is executed in the BPF interpreter: each virtual instruction is converted to a lot of x86_64 instructions inside that interpreter - a lot of CPU time is wasted.
Up-to-date libseccomp library (advanced mitigation for Linux kernel 3.10)
Let’s create the same BPF program directly using libseccomp. I’ve just converted our original JSON file used above to the C code using libseccomp API and howto examples.
#include <seccomp.h>
#include <stdio.h>
#include <errno.h>
#include <unistd.h>
int syscalls[] = {
SCMP_SYS(io_submit),
SCMP_SYS(io_getevents),
SCMP_SYS(rt_sigaction),
SCMP_SYS(nanosleep),
SCMP_SYS(sendto),
SCMP_SYS(pread64),
SCMP_SYS(pwrite64),
SCMP_SYS(wait4),
SCMP_SYS(read),
SCMP_SYS(write),
SCMP_SYS(close),
SCMP_SYS(stat),
SCMP_SYS(stat64),
SCMP_SYS(mmap),
SCMP_SYS(munmap),
SCMP_SYS(open),
SCMP_SYS(fstat),
SCMP_SYS(fstat64),
SCMP_SYS(lstat),
SCMP_SYS(futex),
SCMP_SYS(brk),
SCMP_SYS(clone),
SCMP_SYS(ioctl),
SCMP_SYS(lseek),
SCMP_SYS(getrusage),
SCMP_SYS(getppid),
SCMP_SYS(select),
SCMP_SYS(recvfrom),
SCMP_SYS(rt_sigprocmask),
SCMP_SYS(mprotect),
SCMP_SYS(socket),
SCMP_SYS(connect),
SCMP_SYS(set_robust_list),
SCMP_SYS(set_tid_address),
SCMP_SYS(madvise),
SCMP_SYS(getpriority),
SCMP_SYS(io_setup),
SCMP_SYS(openat),
SCMP_SYS(getrlimit),
SCMP_SYS(getdents),
SCMP_SYS(execve),
SCMP_SYS(access),
SCMP_SYS(arch_prctl),
SCMP_SYS(alarm),
SCMP_SYS(kill),
SCMP_SYS(unlink),
SCMP_SYS(pipe),
SCMP_SYS(creat),
SCMP_SYS(rt_sigreturn),
SCMP_SYS(fcntl),
SCMP_SYS(geteuid),
SCMP_SYS(getuid),
SCMP_SYS(getgid),
SCMP_SYS(readlink),
SCMP_SYS(dup2),
SCMP_SYS(msync),
SCMP_SYS(setsockopt),
SCMP_SYS(rmdir),
SCMP_SYS(vfork),
SCMP_SYS(getpid),
SCMP_SYS(unlinkat),
SCMP_SYS(uname),
SCMP_SYS(newfstatat),
SCMP_SYS(setrlimit),
SCMP_SYS(poll),
SCMP_SYS(umask),
SCMP_SYS(getpgrp),
SCMP_SYS(recvmsg),
SCMP_SYS(chmod),
SCMP_SYS(bind),
SCMP_SYS(chdir),
SCMP_SYS(listen),
SCMP_SYS(getcwd),
SCMP_SYS(faccessat),
SCMP_SYS(fadvise64),
SCMP_SYS(fadvise64_64),
SCMP_SYS(accept),
SCMP_SYS(getsockname),
SCMP_SYS(getgroups),
SCMP_SYS(shmctl),
SCMP_SYS(shmdt),
SCMP_SYS(shmat),
SCMP_SYS(sched_getaffinity),
SCMP_SYS(fsync),
SCMP_SYS(utimensat),
SCMP_SYS(shmget),
SCMP_SYS(gettid),
SCMP_SYS(clock_gettime),
SCMP_SYS(exit_group),
SCMP_SYS(socketpair),
SCMP_SYS(prctl),
SCMP_SYS(setsid),
SCMP_SYS(io_destroy),
SCMP_SYS(setpriority),
SCMP_SYS(getsid),
SCMP_SYS(restart_syscall),
SCMP_SYS(accept4),
SCMP_SYS(capget),
SCMP_SYS(capset),
SCMP_SYS(clock_getres),
SCMP_SYS(clock_nanosleep),
SCMP_SYS(copy_file_range),
SCMP_SYS(dup),
SCMP_SYS(dup3),
SCMP_SYS(epoll_create),
SCMP_SYS(epoll_create1),
SCMP_SYS(epoll_ctl),
SCMP_SYS(epoll_ctl_old),
SCMP_SYS(epoll_pwait),
SCMP_SYS(epoll_wait),
SCMP_SYS(epoll_wait_old),
SCMP_SYS(eventfd),
SCMP_SYS(eventfd2),
SCMP_SYS(execveat),
SCMP_SYS(exit),
SCMP_SYS(fallocate),
SCMP_SYS(fanotify_mark),
SCMP_SYS(fchdir),
SCMP_SYS(fchmod),
SCMP_SYS(fchmodat),
SCMP_SYS(fcntl64),
SCMP_SYS(fdatasync),
SCMP_SYS(fgetxattr),
SCMP_SYS(flistxattr),
SCMP_SYS(flock),
SCMP_SYS(fork),
SCMP_SYS(fremovexattr),
SCMP_SYS(fsetxattr),
SCMP_SYS(fstatat64),
SCMP_SYS(fstatfs),
SCMP_SYS(fstatfs64),
SCMP_SYS(ftruncate),
SCMP_SYS(ftruncate64),
SCMP_SYS(futimesat),
SCMP_SYS(getcpu),
SCMP_SYS(getdents64),
SCMP_SYS(getegid),
SCMP_SYS(getegid32),
SCMP_SYS(geteuid32),
SCMP_SYS(getgid32),
SCMP_SYS(getgroups32),
SCMP_SYS(getitimer),
SCMP_SYS(getpeername),
SCMP_SYS(getpgid),
SCMP_SYS(getrandom),
SCMP_SYS(getresgid),
SCMP_SYS(getresgid32),
SCMP_SYS(getresuid),
SCMP_SYS(getresuid32),
SCMP_SYS(get_robust_list),
SCMP_SYS(getsockopt),
SCMP_SYS(get_thread_area),
SCMP_SYS(gettimeofday),
SCMP_SYS(getuid32),
SCMP_SYS(getxattr),
SCMP_SYS(inotify_add_watch),
SCMP_SYS(inotify_init),
SCMP_SYS(inotify_init1),
SCMP_SYS(inotify_rm_watch),
SCMP_SYS(io_cancel),
SCMP_SYS(ioprio_get),
SCMP_SYS(ioprio_set),
SCMP_SYS(ipc),
SCMP_SYS(lgetxattr),
SCMP_SYS(link),
SCMP_SYS(linkat),
SCMP_SYS(listxattr),
SCMP_SYS(llistxattr),
SCMP_SYS(_llseek),
SCMP_SYS(lremovexattr),
SCMP_SYS(lsetxattr),
SCMP_SYS(lstat64),
SCMP_SYS(memfd_create),
SCMP_SYS(mincore),
SCMP_SYS(mkdir),
SCMP_SYS(mkdirat),
SCMP_SYS(mknod),
SCMP_SYS(memfd_create),
SCMP_SYS(mincore),
SCMP_SYS(mkdir),
SCMP_SYS(mkdirat),
SCMP_SYS(mknod),
SCMP_SYS(mknodat),
SCMP_SYS(mmap2),
SCMP_SYS(mq_getsetattr),
SCMP_SYS(mq_notify),
SCMP_SYS(mq_open),
SCMP_SYS(mq_timedreceive),
SCMP_SYS(mq_timedsend),
SCMP_SYS(mq_unlink),
SCMP_SYS(mremap),
SCMP_SYS(msgctl),
SCMP_SYS(msgget),
SCMP_SYS(msgrcv),
SCMP_SYS(msgsnd),
SCMP_SYS(munlock),
SCMP_SYS(munlockall),
SCMP_SYS(_newselect),
SCMP_SYS(pause),
SCMP_SYS(pipe2),
SCMP_SYS(ppoll),
SCMP_SYS(preadv),
SCMP_SYS(prlimit64),
SCMP_SYS(pselect6),
SCMP_SYS(pwritev),
SCMP_SYS(readahead),
SCMP_SYS(readlinkat),
SCMP_SYS(readv),
SCMP_SYS(recv),
SCMP_SYS(recvmmsg),
SCMP_SYS(remap_file_pages),
SCMP_SYS(removexattr),
SCMP_SYS(rename),
SCMP_SYS(renameat),
SCMP_SYS(renameat2),
SCMP_SYS(rt_sigpending),
SCMP_SYS(rt_sigqueueinfo),
SCMP_SYS(rt_sigsuspend),
SCMP_SYS(rt_sigtimedwait),
SCMP_SYS(rt_tgsigqueueinfo),
SCMP_SYS(sched_getattr),
SCMP_SYS(sched_getparam),
SCMP_SYS(sched_get_priority_max),
SCMP_SYS(sched_get_priority_min),
SCMP_SYS(sched_getscheduler),
SCMP_SYS(sched_rr_get_interval),
SCMP_SYS(sched_setaffinity),
SCMP_SYS(sched_setattr),
SCMP_SYS(sched_setparam),
SCMP_SYS(sched_setscheduler),
SCMP_SYS(sched_yield),
SCMP_SYS(seccomp),
SCMP_SYS(semctl),
SCMP_SYS(semget),
SCMP_SYS(semop),
SCMP_SYS(semtimedop),
SCMP_SYS(send),
SCMP_SYS(sendfile),
SCMP_SYS(sendfile64),
SCMP_SYS(sendmmsg),
SCMP_SYS(sendmsg),
SCMP_SYS(setfsgid),
SCMP_SYS(setfsgid32),
SCMP_SYS(setfsuid),
SCMP_SYS(setfsuid32),
SCMP_SYS(setgid),
SCMP_SYS(setgid32),
SCMP_SYS(setgroups),
SCMP_SYS(setgroups32),
SCMP_SYS(setitimer),
SCMP_SYS(setpgid),
SCMP_SYS(setregid),
SCMP_SYS(setregid32),
SCMP_SYS(setresgid),
SCMP_SYS(setresgid32),
SCMP_SYS(setresuid),
SCMP_SYS(setresuid32),
SCMP_SYS(setreuid),
SCMP_SYS(setreuid32),
SCMP_SYS(set_thread_area),
SCMP_SYS(setuid),
SCMP_SYS(setuid32),
SCMP_SYS(setxattr),
SCMP_SYS(shutdown),
SCMP_SYS(sigaltstack),
SCMP_SYS(signalfd),
SCMP_SYS(signalfd4),
SCMP_SYS(sigreturn),
SCMP_SYS(socketcall),
SCMP_SYS(splice),
SCMP_SYS(statfs),
SCMP_SYS(statfs64),
SCMP_SYS(symlink),
SCMP_SYS(symlinkat),
SCMP_SYS(sync),
SCMP_SYS(sync_file_range),
SCMP_SYS(syncfs),
SCMP_SYS(sysinfo),
SCMP_SYS(syslog),
SCMP_SYS(tee),
SCMP_SYS(tgkill),
SCMP_SYS(time),
SCMP_SYS(timer_create),
SCMP_SYS(timer_delete),
SCMP_SYS(timerfd_create),
SCMP_SYS(timerfd_gettime),
SCMP_SYS(timerfd_settime),
SCMP_SYS(timer_getoverrun),
SCMP_SYS(timer_gettime),
SCMP_SYS(timer_settime),
SCMP_SYS(times),
SCMP_SYS(tkill),
SCMP_SYS(truncate),
SCMP_SYS(truncate64),
SCMP_SYS(ugetrlimit),
SCMP_SYS(utime),
SCMP_SYS(utimes),
SCMP_SYS(vmsplice),
SCMP_SYS(waitid),
SCMP_SYS(waitpid),
SCMP_SYS(writev),
SCMP_SYS(modify_ldt),
SCMP_SYS(chown),
SCMP_SYS(chown32),
SCMP_SYS(fchown),
SCMP_SYS(fchown32),
SCMP_SYS(fchownat),
SCMP_SYS(lchown),
SCMP_SYS(lchown32),
SCMP_SYS(chroot),
SCMP_SYS(reboot),
SCMP_SYS(bpf),
SCMP_SYS(fanotify_init),
SCMP_SYS(lookup_dcookie),
SCMP_SYS(mount),
SCMP_SYS(perf_event_open),
SCMP_SYS(setdomainname),
SCMP_SYS(sethostname),
SCMP_SYS(setns),
SCMP_SYS(umount),
SCMP_SYS(umount2),
SCMP_SYS(unshare),
SCMP_SYS(fchown),
SCMP_SYS(reboot),
};
const size_t syscalls_size = sizeof(syscalls) / sizeof(syscalls[0]);
int main() {
int rc = 0;
scmp_filter_ctx ctx = seccomp_init(SCMP_ACT_ERRNO(1));
if (ctx == NULL) { rc = ENOMEM; goto out; }
rc = seccomp_arch_remove(ctx, SCMP_ARCH_NATIVE);
if (rc != 0) goto out;
rc = seccomp_arch_add(ctx, SCMP_ARCH_X86_64);
if (rc != 0) goto out;
// rc = seccomp_attr_set(ctx, SCMP_FLTATR_CTL_OPTIMIZE, 2);
// if (rc < 0) goto out;
for (size_t i = 0; i < syscalls_size; i++) {
rc |= seccomp_rule_add(ctx, SCMP_ACT_ALLOW, syscalls[i], 0);
}
rc |= seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(personality), 1, SCMP_A0(SCMP_CMP_EQ, 0));
rc |= seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(personality), 1, SCMP_A0(SCMP_CMP_EQ, 8));
rc |= seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(personality), 1, SCMP_A0(SCMP_CMP_EQ, 4294967295));
if (rc < 0) goto out;
seccomp_export_bpf(ctx, STDOUT_FILENO);
out:
seccomp_release(ctx);
return (rc < 0 ? -rc : rc);
}
Note, I’ve commented out the up-to-date binary tree optimization. Let’s check the BPF assembler:
[host]$ gcc -O3 -g genbpf.cc -I ./libseccomp/include ./libseccomp/lib/libseccomp.a -o genbpf
[host]$ ./genbpf | $libseccomp_sources_path/scmp_bpf_disasm
line OP JT JF K
=================================
0000: 0x20 0x00 0x00 0x00000004 ld $data[4]
0001: 0x15 0x00 0x03 0xc000003e jeq 3221225534 true:0002 false:0005
0002: 0x20 0x00 0x00 0x00000000 ld $data[0]
0003: 0x35 0x00 0x02 0x40000000 jge 1073741824 true:0004 false:0006
0004: 0x15 0x01 0x00 0xffffffff jeq 4294967295 true:0006 false:0005
0005: 0x06 0x00 0x00 0x00000000 ret KILL
0006: 0x15 0x1b 0x00 0x00000000 jeq 0 true:0034 false:0007
0007: 0x15 0x1a 0x00 0x00000001 jeq 1 true:0034 false:0008
0008: 0x15 0x19 0x00 0x00000002 jeq 2 true:0034 false:0009
0009: 0x15 0x18 0x00 0x00000003 jeq 3 true:0034 false:0010
0010: 0x15 0x17 0x00 0x00000004 jeq 4 true:0034 false:0011
0011: 0x15 0x16 0x00 0x00000005 jeq 5 true:0034 false:0012
0012: 0x15 0x15 0x00 0x00000006 jeq 6 true:0034 false:0013
....
0032: 0x15 0x01 0x00 0x0000001a jeq 26 true:0034 false:0033
0033: 0x15 0x00 0x01 0x0000001b jeq 27 true:0034 false:0035
0034: 0x06 0x00 0x00 0x7fff0000 ret ALLOW
0035: 0x15 0xff 0x00 0x0000001c jeq 28 true:0291 false:0036
0036: 0x15 0xfe 0x00 0x0000001d jeq 29 true:0291 false:0037
....
0282: 0x15 0x08 0x00 0x00000146 jeq 326 true:0291 false:0283
0283: 0x15 0x00 0x06 0x00000087 jeq 135 true:0284 false:0290
0284: 0x20 0x00 0x00 0x00000014 ld $data[20]
0285: 0x15 0x00 0x04 0x00000000 jeq 0 true:0286 false:0290
0286: 0x20 0x00 0x00 0x00000010 ld $data[16]
0287: 0x15 0x03 0x00 0xffffffff jeq 4294967295 true:0291 false:0288
0288: 0x15 0x02 0x00 0x00000008 jeq 8 true:0291 false:0289
0289: 0x15 0x01 0x00 0x00000000 jeq 0 true:0291 false:0290
0290: 0x06 0x00 0x00 0x00050001 ret ERRNO(1)
0291: 0x06 0x00 0x00 0x7fff0000 ret ALLOW
0292: 0x06 0x00 0x00 0x00000000 ret KILL
The same O(n) chain, the assembler here is a bit different, because the Linux kernel makes some modifications inside itself: to the operation codes mostly. Just notice, that all the addresses here are absolute, not relative as it was in kernel BPF version.
Using the binary tree optimization (return back seccomp_attr_set(ctx, SCMP_FLTATR_CTL_OPTIMIZE, 2), recompile, disassemble):
line OP JT JF K
=================================
0000: 0x20 0x00 0x00 0x00000004 ld $data[4]
0001: 0x15 0x00 0x03 0xc000003e jeq 3221225534 true:0002 false:0005
0002: 0x20 0x00 0x00 0x00000000 ld $data[0]
0003: 0x35 0x00 0x02 0x40000000 jge 1073741824 true:0004 false:0006
0004: 0x15 0x01 0x00 0xffffffff jeq 4294967295 true:0006 false:0005
0005: 0x06 0x00 0x00 0x00000000 ret KILL
0006: 0x20 0x00 0x00 0x00000000 ld $data[0]
0007: 0x25 0x01 0x00 0x00000014 jgt 20 true:0009 false:0008
0008: 0x05 0x00 0x00 0x00000147 jmp 0336
0009: 0x25 0x00 0xa1 0x0000009d jgt 157 true:0010 false:0171
0010: 0x25 0x00 0x4f 0x000000f5 jgt 245 true:0011 false:0090
0011: 0x25 0x00 0x27 0x0000011b jgt 283 true:0012 false:0051
0012: 0x25 0x00 0x13 0x0000012b jgt 299 true:0013 false:0032
0013: 0x25 0x00 0x09 0x0000013a jgt 314 true:0014 false:0023
0014: 0x25 0x00 0x04 0x0000013e jgt 318 true:0015 false:0019
0015: 0x15 0x5a 0x00 0x00000146 jeq 326 true:0106 false:0016
0016: 0x15 0x59 0x00 0x00000142 jeq 322 true:0106 false:0017
0017: 0x15 0x58 0x00 0x00000141 jeq 321 true:0106 false:0018
0018: 0x15 0x57 0x53 0x0000013f jeq 319 true:0106 false:0102
...
0101: 0x15 0x04 0x00 0x000000ea jeq 234 true:0106 false:0102
0102: 0x06 0x00 0x00 0x00050001 ret ERRNO(1)
0103: 0x25 0x00 0x05 0x000000e5 jgt 229 true:0104 false:0109
0104: 0x15 0x01 0x00 0x000000e9 jeq 233 true:0106 false:0105
0105: 0x15 0x00 0x01 0x000000e8 jeq 232 true:0106 false:0107
0106: 0x06 0x00 0x00 0x7fff0000 ret ALLOW
0107: 0x15 0xff 0x00 0x000000e7 jeq 231 true:0363 false:0108
...
0359: 0x15 0x03 0x00 0x00000002 jeq 2 true:0363 false:0360
0360: 0x15 0x02 0x01 0x00000001 jeq 1 true:0363 false:0362
0361: 0x15 0x01 0x00 0x00000000 jeq 0 true:0363 false:0362
0362: 0x06 0x00 0x00 0x00050001 ret ERRNO(1)
0363: 0x06 0x00 0x00 0x7fff0000 ret ALLOW
0364: 0x06 0x00 0x00 0x00000000 ret KILL
As you can see, the algorithm is changed from O(n) to O(log n), where n - is the number of system calls to test.
How to use the custom libseccomp (advanced mitigation for Linux kernel 3.10)
The easiest way I have found so far is to utilize the /bin/env approach: change the environment, then execve the child process. Let’s create the seccomp.bintree utility, the code above should be slightly modified:
#include <seccomp.h>
#include <stdio.h>
#include <errno.h>
#include <unistd.h>
int syscalls[] = {
// .... //
};
const size_t syscalls_size = sizeof(syscalls) / sizeof(syscalls[0]);
int apply_seccomp() {
int rc = 0;
scmp_filter_ctx ctx = seccomp_init(SCMP_ACT_ERRNO(1));
if (ctx == NULL) { rc = ENOMEM; goto out; }
rc = seccomp_arch_remove(ctx, SCMP_ARCH_NATIVE);
if (rc != 0) goto out;
rc = seccomp_arch_add(ctx, SCMP_ARCH_X86_64);
if (rc != 0) goto out;
rc = seccomp_attr_set(ctx, SCMP_FLTATR_CTL_OPTIMIZE, 2);
if (rc < 0) goto out;
for (size_t i = 0; i < syscalls_size; i++) {
rc |= seccomp_rule_add(ctx, SCMP_ACT_ALLOW, syscalls[i], 0);
}
rc |= seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(personality), 1, SCMP_A0(SCMP_CMP_EQ, 0));
rc |= seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(personality), 1, SCMP_A0(SCMP_CMP_EQ, 8));
rc |= seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(personality), 1, SCMP_A0(SCMP_CMP_EQ, 4294967295));
if (rc < 0) goto out;
rc = seccomp_load(ctx);
if (rc < 0) {
perror("seccomp_load failed");
goto out;
}
printf("SECCOMP APPLIED\n");
out:
seccomp_release(ctx);
return (rc < 0 ? -rc : rc);
}
int main(int argc, char **argv, char **env) {
if (argc < 2) {
printf("Specify child process");
return -1;
}
int rc = apply_seccomp();
if (rc < 0) {
printf("apply_seccomp() failed\n");
return rc;
}
return execve(argv[1], argv + 1, env);
}
So, let’s use the benchmark from Reproducing the problem section for the seccomp.bintree (the code represented above) and seccomp.default (without binary tree optimization) and the docker container without the security restrictions at all (we implement the security manually by ourselves):
[host]$ docker run --security-opt seccomp=unconfined -v$HOME:$HOME -it $euler_os_container /bin/bash
[container]$ ./seccomp.default ./inf
SECCOMP APPLIED
[container]$ ./seccomp.bintree ./inf
SECCOMP APPLIED
Then we do the perf record/perf report as usual.
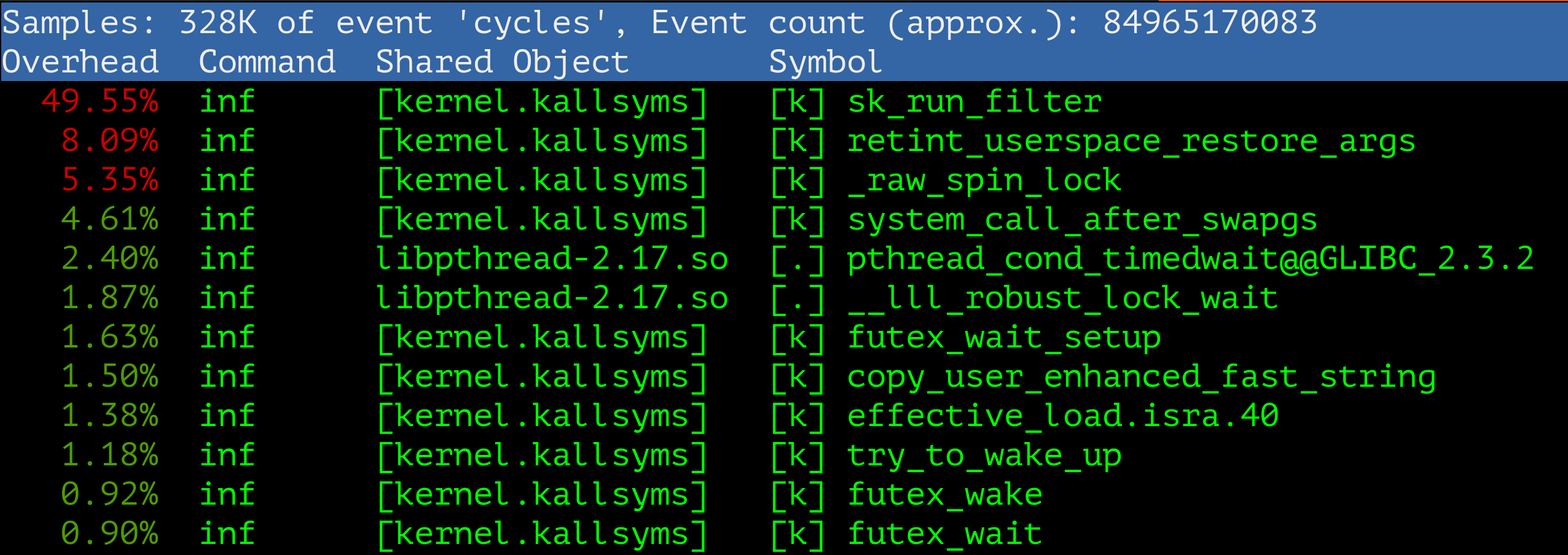
seccomp.default:
seccomp.bintree:
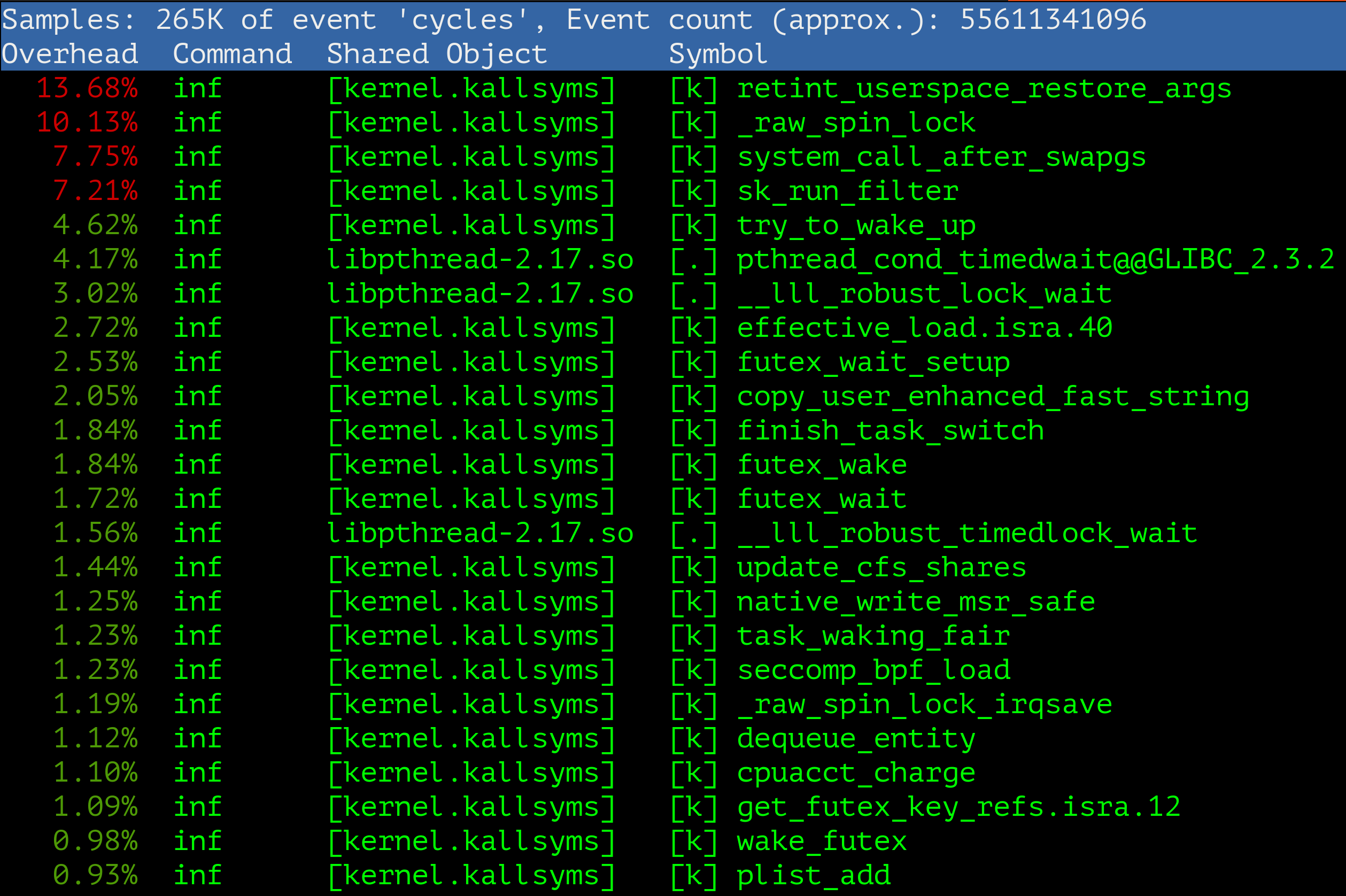
sk_run_filter CPU consumption in Linux kernel 3.10 dropped from 50% to 7% which is like a lot!
A few words about Linux kernel 5.15
The security computing feature is further optimized in the Linux kernel 5.15 using bitmap cache. The optimization is done for a whitelist approach. The idea is very simple. When BPF code is uploaded to the kernel (prctl or seccomp system calls), the bitmap is allocated for each existing system call. If the BPF code for a particular system call always returns the SECCOMP_RET_ALLOW regardless its arguments, the corresponding bit is set in the cache. Afterwards, for such system calls the JIT-compiled BPF program isn’t executed at all, the “allow” result is returned immediately.
To my opinion, this final patch eventually solved the original issue completely. As usual, the proof is got from the Linux kernel sources:
/**
* seccomp_run_filters - evaluates all seccomp filters against @sd
* @sd: optional seccomp data to be passed to filters
* @match: stores struct seccomp_filter that resulted in the return value,
* unless filter returned SECCOMP_RET_ALLOW, in which case it will
* be unchanged.
*
* Returns valid seccomp BPF response codes.
*/
#define ACTION_ONLY(ret) ((s32)((ret) & (SECCOMP_RET_ACTION_FULL)))
static u32 seccomp_run_filters(const struct seccomp_data *sd,
struct seccomp_filter **match)
{
u32 ret = SECCOMP_RET_ALLOW;
/* Make sure cross-thread synced filter points somewhere sane. */
struct seccomp_filter *f =
READ_ONCE(current->seccomp.filter);
/* Ensure unexpected behavior doesn't result in failing open. */
if (WARN_ON(f == NULL))
return SECCOMP_RET_KILL_PROCESS;
if (seccomp_cache_check_allow(f, sd)) // << -- HERE
return SECCOMP_RET_ALLOW;
/*
* All filters in the list are evaluated and the lowest BPF return
* value always takes priority (ignoring the DATA).
*/
for (; f; f = f->prev) {
u32 cur_ret = bpf_prog_run_pin_on_cpu(f->prog, sd);
if (ACTION_ONLY(cur_ret) < ACTION_ONLY(ret)) {
ret = cur_ret;
*match = f;
}
}
return ret;
}
/* .... */
static inline bool seccomp_cache_check_allow_bitmap(const void *bitmap,
size_t bitmap_size,
int syscall_nr)
{
if (unlikely(syscall_nr < 0 || syscall_nr >= bitmap_size))
return false;
syscall_nr = array_index_nospec(syscall_nr, bitmap_size);
return test_bit(syscall_nr, bitmap);
}
/**
* seccomp_cache_check_allow - lookup seccomp cache
* @sfilter: The seccomp filter
* @sd: The seccomp data to lookup the cache with
*
* Returns true if the seccomp_data is cached and allowed.
*/
static inline bool seccomp_cache_check_allow(const struct seccomp_filter *sfilter,
const struct seccomp_data *sd)
{
int syscall_nr = sd->nr;
const struct action_cache *cache = &sfilter->cache;
#ifndef SECCOMP_ARCH_COMPAT
/* A native-only architecture doesn't need to check sd->arch. */
return seccomp_cache_check_allow_bitmap(cache->allow_native,
SECCOMP_ARCH_NATIVE_NR,
syscall_nr);
#else
if (likely(sd->arch == SECCOMP_ARCH_NATIVE))
return seccomp_cache_check_allow_bitmap(cache->allow_native,
SECCOMP_ARCH_NATIVE_NR,
syscall_nr);
if (likely(sd->arch == SECCOMP_ARCH_COMPAT))
return seccomp_cache_check_allow_bitmap(cache->allow_compat,
SECCOMP_ARCH_COMPAT_NR,
syscall_nr);
#endif /* SECCOMP_ARCH_COMPAT */
WARN_ON_ONCE(true);
return false;
}
The bitmap cache is prepared in these three functions:
/**
* seccomp_cache_prepare - emulate the filter to find cacheable syscalls
* @sfilter: The seccomp filter
*
* Returns 0 if successful or -errno if error occurred.
*/
static void seccomp_cache_prepare(struct seccomp_filter *sfilter)
{
struct action_cache *cache = &sfilter->cache;
const struct action_cache *cache_prev =
sfilter->prev ? &sfilter->prev->cache : NULL;
seccomp_cache_prepare_bitmap(sfilter, cache->allow_native,
cache_prev ? cache_prev->allow_native : NULL,
SECCOMP_ARCH_NATIVE_NR,
SECCOMP_ARCH_NATIVE);
#ifdef SECCOMP_ARCH_COMPAT
seccomp_cache_prepare_bitmap(sfilter, cache->allow_compat,
cache_prev ? cache_prev->allow_compat : NULL,
SECCOMP_ARCH_COMPAT_NR,
SECCOMP_ARCH_COMPAT);
#endif /* SECCOMP_ARCH_COMPAT */
}
/* ...... */
static void seccomp_cache_prepare_bitmap(struct seccomp_filter *sfilter,
void *bitmap, const void *bitmap_prev,
size_t bitmap_size, int arch)
{
struct sock_fprog_kern *fprog = sfilter->prog->orig_prog;
struct seccomp_data sd;
int nr;
if (bitmap_prev) {
/* The new filter must be as restrictive as the last. */
bitmap_copy(bitmap, bitmap_prev, bitmap_size);
} else {
/* Before any filters, all syscalls are always allowed. */
bitmap_fill(bitmap, bitmap_size);
}
for (nr = 0; nr < bitmap_size; nr++) {
/* No bitmap change: not a cacheable action. */
if (!test_bit(nr, bitmap))
continue;
sd.nr = nr;
sd.arch = arch;
/* No bitmap change: continue to always allow. */
if (seccomp_is_const_allow(fprog, &sd)) // <<----- HERE
continue;
/*
* Not a cacheable action: always run filters.
* atomic clear_bit() not needed, filter not visible yet.
*/
__clear_bit(nr, bitmap);
}
}
/* ...... */
/**
* seccomp_is_const_allow - check if filter is constant allow with given data
* @fprog: The BPF programs
* @sd: The seccomp data to check against, only syscall number and arch
* number are considered constant.
*/
static bool seccomp_is_const_allow(struct sock_fprog_kern *fprog,
struct seccomp_data *sd)
{
unsigned int reg_value = 0;
unsigned int pc;
bool op_res;
if (WARN_ON_ONCE(!fprog))
return false;
for (pc = 0; pc < fprog->len; pc++) {
struct sock_filter *insn = &fprog->filter[pc];
u16 code = insn->code;
u32 k = insn->k;
switch (code) {
case BPF_LD | BPF_W | BPF_ABS:
switch (k) {
case offsetof(struct seccomp_data, nr):
reg_value = sd->nr;
break;
case offsetof(struct seccomp_data, arch):
reg_value = sd->arch;
break;
default:
/* can't optimize (non-constant value load) */
return false;
}
break;
case BPF_RET | BPF_K:
/* reached return with constant values only, check allow */
return k == SECCOMP_RET_ALLOW;
case BPF_JMP | BPF_JA:
pc += insn->k;
break;
case BPF_JMP | BPF_JEQ | BPF_K:
case BPF_JMP | BPF_JGE | BPF_K:
case BPF_JMP | BPF_JGT | BPF_K:
case BPF_JMP | BPF_JSET | BPF_K:
switch (BPF_OP(code)) {
case BPF_JEQ:
op_res = reg_value == k;
break;
case BPF_JGE:
op_res = reg_value >= k;
break;
case BPF_JGT:
op_res = reg_value > k;
break;
case BPF_JSET:
op_res = !!(reg_value & k);
break;
default:
/* can't optimize (unknown jump) */
return false;
}
pc += op_res ? insn->jt : insn->jf;
break;
case BPF_ALU | BPF_AND | BPF_K:
reg_value &= k;
break;
default:
/* can't optimize (unknown insn) */
return false;
}
}
/* ran off the end of the filter?! */
WARN_ON(1);
return false;
}
If you are still with me, here and actually reading these lines, my goal is achieved: now you know everything about secure computing feature in Linux :)
References
- https://kernel.org/
- https://elixir.bootlin.com/
- https://developer.huaweicloud.com/ict/en/site-euleros/euleros
- https://gist.github.com/fntlnz/08ae20befb91befd9a53cd91cdc6d507
- https://docs.docker.com/engine/security/seccomp/
- https://blog.sourcerer.io/writing-a-simple-linux-kernel-module-d9dc3762c234



Comments